
분산 시스템, 마이크로서비스 아키텍처와 같은 개념들을 이야기하다 보면 빠지지 않는 것이 비동기 통신과 메시지 큐입니다. 대부분 메시지큐 기반 비동기 통신을 통해서 서비스간의 결합도를 낮춘다고 합니다. 우아한 중계서비스에서도 메시지큐를 활용한 비동기 통신을 고려하며 찾아본 내용들을 적어두었습니다.

Table of Contents
- 메시지 큐를 통해 해결하려는 문제는?
- 디커플링(decopuling), 서비스 간의 결합도 감소
- 관심사의 분리를 통한 처리시간 최적화
- 트래픽 완충제 역할
- 메시지 큐 활용시 해결해야 하는 문제는?
- 시스템 가용성 감소 Availability
- 시스템 복잡도 증가 Complexity
- 데이터 일관성 문제 Consistency
- Cheography-based Saga
- Orchestration-based Saga
- 메시지큐 적용을 위한 고려사항
- Delivery-Guarantee (전송, 전달 보증)
- exactly-once
- at-most -once 와 at-least-once
- Persistency (영속성) & Durability (내구성)
- 메시지큐의 Persistence 영속성
- 메시지큐의 Durability 내구성
- Ordering (순서)
- Filtering & Routing (필터링, 라우팅)
- Delivery-Guarantee (전송, 전달 보증)
- 마치며
- 참고자료
메시지 큐를 통해 해결하려는 문제는?
메시지 큐로 해결할 수 있는 문제들은 어떤 것들이 있을까요?
메시지 큐의 장점 세 가지 디커플링(decoupling), 비동기 (asynchronous), 트래픽 조절(peak-clipping)을 통해 살펴보겠습니다.
# 디커플링(decopuling), 서비스 간의 결합도 감소
Synchronous 한 통신 : 높은 결합도
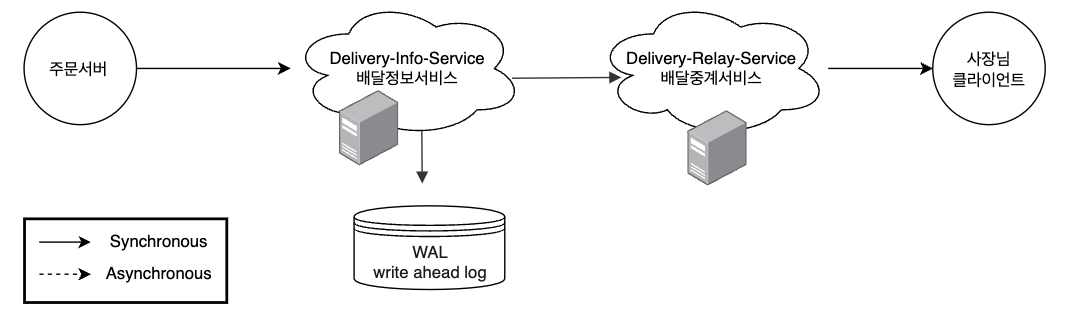
위 다이어그램의 시스템은 Synchronous 해서 결합도가 높은 시스템의 예시입니다. 각 서비스간의 통신은 HTTP로 Synchronous 하게 통신하며 마치 여러 서버들로 구성된 하나의 거대한 메소드처럼 보이기도 합니다.
이러한 형태로 통신하는 상황에서는 애플리케이션의 버그, 간헐적인 네트워크 연결 실패, 데이터센터의 정전, 데이터 손실, 자연재해 등의 요인으로 인해 하나의 서비스라도 실패한다면 Synchronous 하게 통신되는 모든 서비스들이 실패하게 됩니다.
Asynchronous 한 통신 : 낮은 결합도
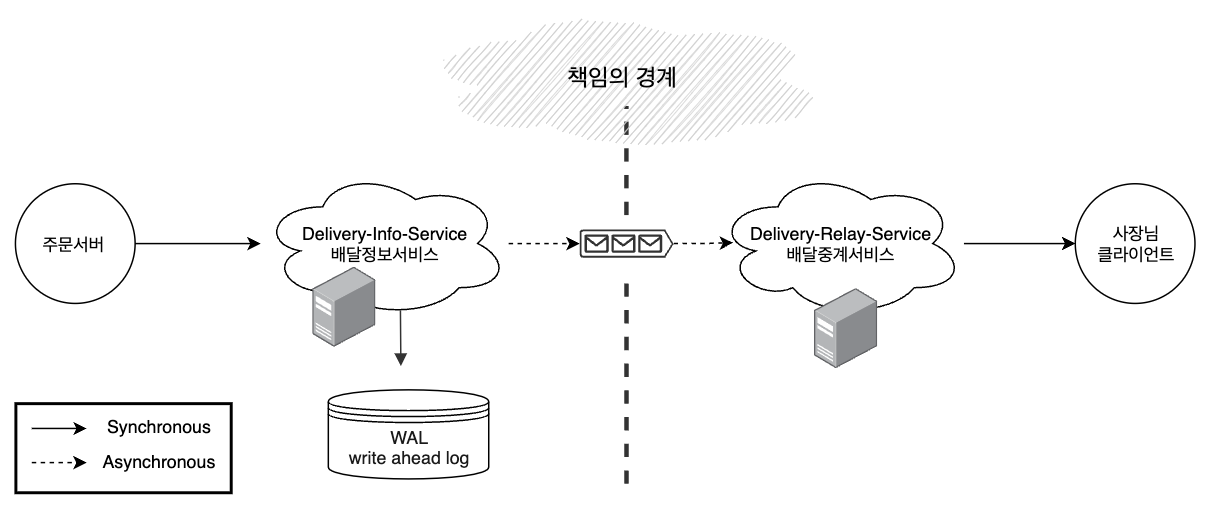
그에 반면 비동기 메시징으로 통신을 하면 서비스 간의 결합도를 감소시킬 수 있습니다. 메시징에서 서비스들은 메시지큐에 발행/구독 하는 것으로 본인의 책임을 다하기 때문입니다. 아키텍처 레벨에서 본다면 메시지큐를 통해 서비스간 책임의 경계를 지정할 수 있다고 생각할 수 있겠습니다.
# 비동기통신을 통한 성능 최적화 : Asynchronous
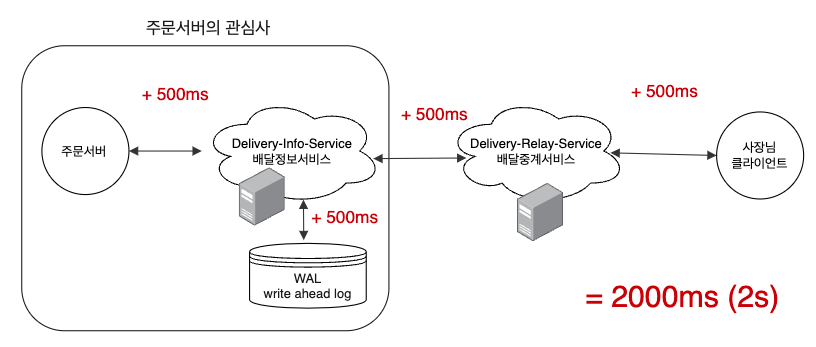
Synchronous 한 서비스들은 요청하거나 응답하는 과정에서 본인 관심사가 아닌 작업들까지 기다리게 되는 경우가 있어서 요청 처리시간이 길어지게 됩니다. 위 다이어그램을 예시로 살펴보겠습니다.
주문 서버는 새로 발생한 주문을 배달정보서비스까지만 전달하면 되는데, 배달정보서비스에서는 배달중계서비스까지 주문 정보를 전달하고, 또 배달중계서비스는 주문정보를 사장님 클라이언트까지 전달하고 있습니다.
이렇게 연쇄적으로 리턴으을 기다리다 보니 당연히 처리시간이 길어집니다. 병목이 전파되고, Latency는 증가하고 결과적으로는 고객만족도도 하락합니다. 너무 배고픈데 주문은 왜 이렇게 확인을 안 하는지....? 정말 필요한 부분만 동기로 두고 나머지는 비동기로 처리하면 어떻게 될까요?
Asynchronous 로 이루는 성능 최적화
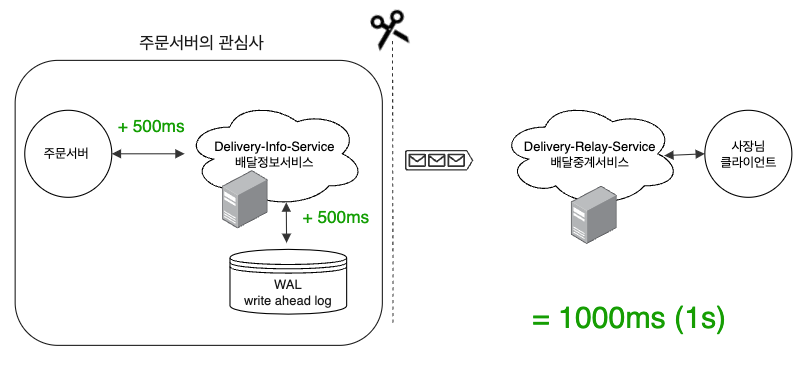
비동기 메시징 적용에 대한 효과를 위의 예시를 통해 살펴보겠습니다. 적용 시 주문 서버에서 배달정보서비스로 주문을 전달하고, WAL의 역할을 수행하는 데이터베이스에 저장된 것까지만 확인하면 200 OK 응답을 받을 수 있습니다. 그 외 Relay-Service에게 전달, 사장님에게 전달 등의 작업들은 비동기로 진행되고 서비스의 관심사별로 작업들이 분리되며 서로의 시간을 절약하는 효과를 일으킵니다.
# 트래픽 완충제 역할 : Peak-Clipping
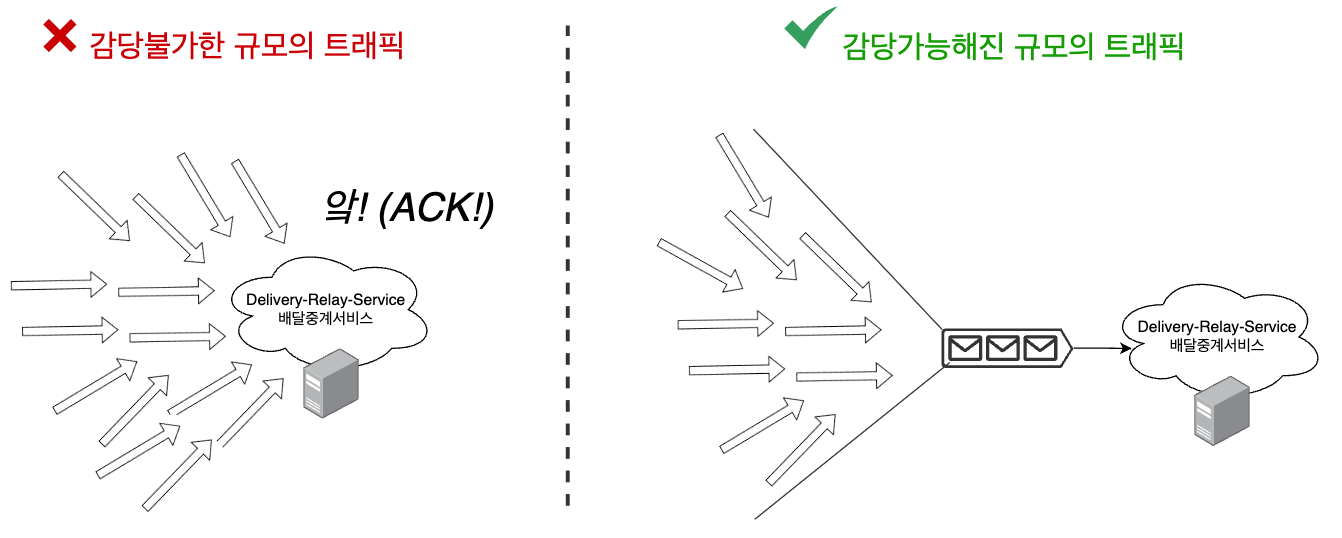
일시적으로 서버들이 감당 불가능한 규모의 트래픽이 발생하면 어떻게 될까요? Failure가 최선일까요? Scale Up? Scale Out?
AutoScaling 적용을 위해 고려해야 할 부분은 무엇이 잇을까요? 스케일하는 동안 사용자 요청들은 전부 Timeout 처리되어야 하나요? 서비스의 start-up time은? 서비스의 Warm-up 시간은? 스케일하기 위해 추적하는 지표는 몇 초 단위, 혹은 몇 밀리세컨드 단위의 빈도로 모니터링되는지? ASG가 생성하는 인스턴스는 얼마나 몇 ms 안에 RUNNING 상태에 들어가는지?
수평적, 수직적 스케일링은 모두 순간적(instantaneous)이지 못하기 때문에 트래픽이 밀리세컨드 단위로 폭발하는 서비스의 경우 단순 스케일링 방식은 해결방안이 될 수 없다는 것을 깨닫게 됩니다. 대신 메시지 큐로 해결 서비스의 앞에서 Buffer 처럼 트래픽을 받아들이고 consumer-side의 서비스들은 각자 최선을 다해 순차적으로 처리하는 접근 방법을 생각해볼 수 있습니다.
메시지 큐 활용 시 단점
이번에는 메시지큐를 활용할 경우 해결해야 하는 문제점에 대해서 살펴보겠습니다.
# 시스템 가용성 감소 Availability
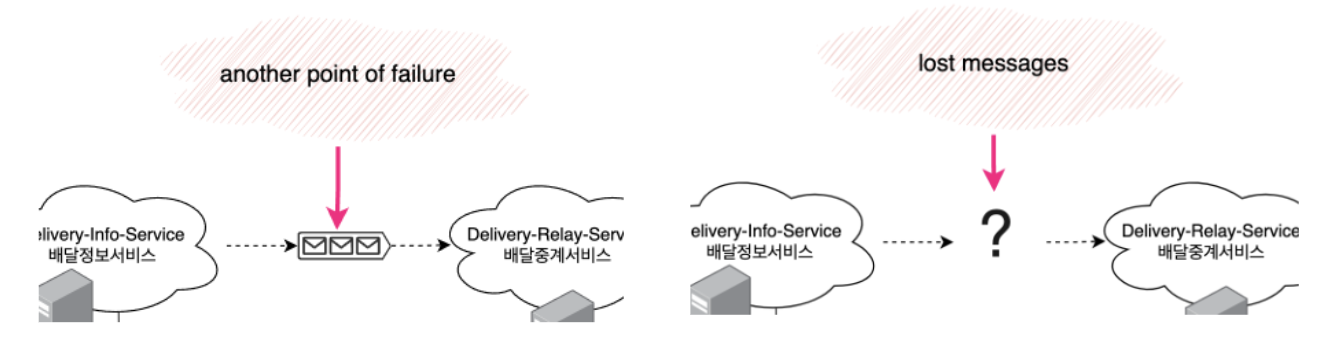
서비스 간 비동기 통신으로 결합도를 낮추는데 availability도 감소한다? 는 말은 다소 모순되게 들릴 수도 있겠습니다. 메시지큐 도입시에는 메시지큐의 장애와 메시지의 유실까지 감안해서 서비스를 설계해야합니다.
# 시스템 복잡도 증가 Complexity
아래 메시지큐와 관련된 고려사항들 몇 가지들을 하나씩 살펴보겠습니다.
- Data Consistency (데이터 일관성***)
- Delivery-Guarantee (전송, 전달 보증)
- Persistency (영속성) & Durability (내구성)
- Ordering (순서)
- Filtering & Routing (필터링, 라우팅)
- Availability, Scalability, Performance (가용성, 확장성, 성능)
메시지큐를 도입하는 개발자의 머리속
메시지는 몇 번 전달(시도)할 수 있는지? 전달이 안 되는 경우에는?
중복처리는 어느 서비스에서, 어떻게 할지? 왜 그 서비스에서 해야 하는지?
데이터에 순서가 필요한지?
유실된 메시지는 어떻게 처리해야 하는지?유실이 안되게 하려면 어떤 방법이 있을지? 유실 가능한 정도는?
메시지 프로토콜은?
몇 ms안에 전달이 돼야 하는지?
특정 메시지큐를 적용 시 고려해야 하는 부분들은 무엇인지? 지원해주는 부분은 어떤 것들이 있는지?
또는 서비스에서 별도의 핸들링이 필요한 부분인지?
다른 대안은 무엇이 있는지?
# 데이터 일관성 문제 Consistency
비즈니스에서 가장 중요한 것은 무엇일까요? 데이터의 일관성입니다. 사용자가 쿠폰을 사용하면 쿠폰이 사용되어야하고 주문을 하면 주문이 전달되어야하고 그 모든 이벤트들 중심에 서 있(었던)는 것이 바로 데이터의 일관성, 트랜잭션과 ACID 입니다. 트랜잭션과 ACID 를 보장받는 시스템은 상대적으로 간결하고 개발하기도 매우 편합니다.
메시지큐가 많이 사용되는 분산시스템, 마이크로서비스 아키텍처의 경우 데이터 소스가 물리적으로 분리되어있는 경우가 많기 때문에 트랜잭션의 일관성을 유지하기 어렵습니다. 그래서 나타난 것이 BASE라는 키워드입니다. Basically Available, Soft State, Eventually Consistent로 구성된 BASE, 찾아보면 도움이 될 것으로 보입니다.
분산 시스템에서 데이터 일관성을 유지하는 방법으로는 분산 트랜잭션(Distributed Transaction)과 궁극적 일관성(eventual consistency)이 있습니다.
분산 트랜잭션은 all or nothing 으로 분산된 데이터소스들을 2-phase commit 방식의 트랜잭션으로 묶는 것이지만 성능적인 문제, 네트워크의 불안정성, 서비스간 높은 결합도 때문에 사용이 되지 않습니다.
궁극적 일관성 유지를 위한 방법으로는 Saga 패턴이 가장 많이 언급되는데요, Saga 패턴은 비동기 메시징을 활용하며 여러 서비스들의 로컬 트랜잭션을 순차적으로 실행되게 함으로써 데이터 일관성을 유지하는 방법입니다.
Saga 패턴은 다시 Choreography-based와 Orchestration-based 두 가지 방법으로 나뉩니다. 이 외에도 여러 Distributed Transaction 관리 전략이 있으며 참고를 위해 RedHat의 기술 블로그에서 소개하는 방법 몇 가지 링크 남겨둡니다.
Cheography-based Saga
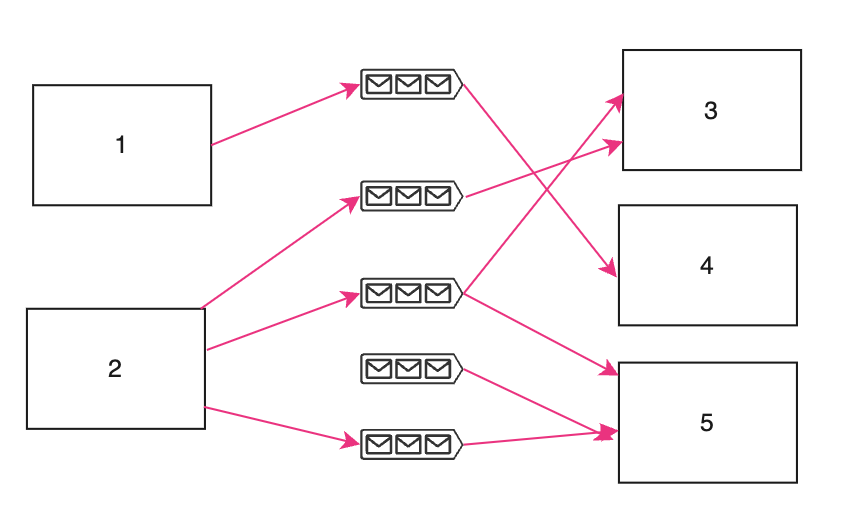
Choreography-based saga의 경우 saga에 참여하는 각 서비스들이 서로 통신하면서 데이트의 일관성을 맞춰나가는 방법입니다.
Choreography 방식의 장점은 단순함과 낮은 결합도입니다. 각 서비스에서 필요한 이벤트를 발행하고 구독하기 때문에 단순하며 메시지큐를 활용해서 낮은 결합도(decoupled-ness)를 유지할 수 있습니다.
Choreography 방식의 단점은 서비스의 규모가 커질수록 장점들이 되려 치명적인 단점이 될 수 있다는 점입니다. Saga 참여자가 많아질수록 각 서비스 간의 contract(통신 계약)를 관리하기가 복잡해지며, 서로가 서로의 이벤트를 구독하는 순환 참조가 발생하고 디자인 품질이 떨어지게 됩니다. 게다가 여러 서비스가 직접적으로 Workflow 로직을 관리하다 보니 workflow와 서비스 간, 그리고 서비스와 서비스 간의 결합도가 높아지는 단점이 있습니다. 이러한 Choreography 방식의 단점들은 규모가 커질수록 N^2로 커져갑니다.
워크플로우가 정말 단순하거나 작은 규모의 Saga를 적용하는 경우, 또는 서비스 규모가 증가되지 않을 것이 예상되는 경우 Choreography-based saga 패턴을 고려해보는 것이 바람직해 보입니다.
Orchestration-based Saga
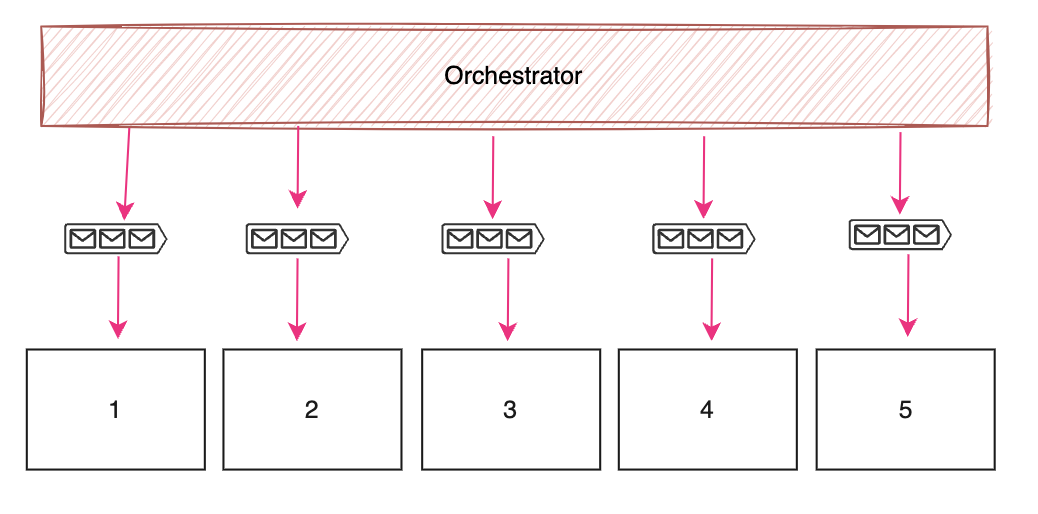
Orchestrated 방식에서는 사용자가 지정한 Orchestrator에 의해 centralized 한 방식으로 워크플로우가 실행됩니다.
Orchestration의 장점은 의존관계의 명확함, 낮은 결합도, 관심사의 분리, 그리고 비즈니스 로직의 간소화입니다. Orchestration에서 워크플로우 관련 로직들은 Orchestrator로 분리시켜 서비스 디펜던시가 위 다이어그램의 화살표처럼 단방향으로 명확합니다. 이런 명료한 서비스 구조는 빠르게 확장되는 서비스 확장에 있어 커다란 장점으로 적용됩니다. 그리고 워크플로우 관련 로직이 Orchestrator로 분리되어 서비스들은 상대적으로 가벼워지는 효과를 볼 수 있습니다.
Orchestration의 단점은 Orchestrator가 단일 실패 지점이 될 수 있다는 점입니다. 워크플로우의 흐름을 관리하기 때문에 failure 발생 시 서비스 자체가 불가능할 수 있습니다. Orchestration의 다른 단점은 비즈니스 로직이 Orchestrator에 집중될 리스크가 있다는 점입니다. Orchestration 적용 시 워크플로우 관리 로직만 Orchestrator 서비스에 추가되어야하는데 역할 분담을 철저히 하지 않는다면 많은 로직들이 Orchestrator로 쏠리고 나머지 서비스들은 Orchestrator 없이는 쓸모없어지는 양극화가 발생할 수 있습니다.
Orchestration-based Saga 패턴의 강점들은 서비스의 규모에 커질수록 매력적이기 때문에 상대적으로 많이 사용되는 추세입니다. 적용시 Orchestrator의 Failover를 탄탄히 구성하며 SPOF(단일실패지점)으로 전락하는 것을 예방하고 Orchestrator에 추가되는 로직들을 철저히 관리함으로써 최선의 결과를 낼 수 있을 것으로 보입니다.
# Delivery-Guarantee (전송,전달보증)
at-most-once delivery 최대 한번
at-least-once delivery 최소 한번
exactly-once delivery 정확히 한번 (effectively-once)
Delivery-Guarantee의 정의는 중요하지만 틀리게 설명할 가능성이 크기 때문에 제가 설명하지는 않겠습니다. 대신 키워드만 공유드리자면 delivery(배달, 전송)의 기준이 무엇인지, 메시지 publish 된다는 것의 기준은 정확히 무엇인지, subscriber에게 메시지가 전달됐다는 것의 기준은 무엇인지, duplicate writes, duplicate reads 등의 콘셉트들을 찾아보시는 것을 추천드립니다.
네, 그래서 delivery-guarantee에 대해서 이야기해보겠습니다. 메시징 서비스를 찾아볼 때는 보통 위 세 가지delivery guarantee를 많이 접하게 됩니다. 사실 모두가 바라는 것은 exactly-once, 정확히 한번 전달되는 guarantee입니다. 그렇다면 왜 at-most-once와 at-least-once가 존재하는 것일까요?
메시지가 생성되고 처리 되까지 delivery를 방해하는 많은 요인들이 존재합니다. 중복 또는 다중 쓰기, 입력 레코드 다시 읽기, partial failure, network failure, 패킷 유실, ack 유실 등의 여러 요인으로 exactly-once delivery 사실상 best-effort 라고 생각하는 것이 바람직하다고 볼 수 있겠습니다.
exactly-once를 감안하고 구성한 서비스의 구조는 정말 간결할 것이고 매력적이기 때문에 많은 메시징 서비스들이 exactly-once에 가까워지기 위해 끊임없이 노력하고 있는데요, 실제로 AWS SQS 나 Apache Kafka에서는 excatly-once delivery를 지원합니다.
*** Apache Kafka에서 제공하는 exactly-once는 Idempotent Producer, Transactions Across Partitions, Transactional Consumer 등의 기능/개념들을 활용합니다. 자세한 사항은 Confluent가 소개하는 Apache Kafka의 exactly-once delivery 블로그를 읽어보는 것을 추천드립니다.
결국 궁극적인 목표는 메시지의 전달입니다. 각 메시지의 중요도가 높아질수록 delivery-guarantee를 전제한 부분과 guarantee의 실패까지 고려한 설계가 요구됩니다.
exactly-once
exactly-once를 전제로 비동기 통신을 구성하는 경우 Apache Kafka, 또는 AWS SQS를 많이 사용하는 것으로 보입니다. 다른 메시징 서비스들은 exactly-once delivery 지원을 안 하거나 아직 premature 한 상태이기 때문에 서비스 단위의 failover가 복잡해지는 리스크가 있습니다. 예를 들어 Apache Kafka의 exactly-once를 활용한다면 비즈니스 로직들이 exactly-once에 의존하게 되겠지요.
at-most once와 at-least-once
exactly-once라는 개념을 다소 비관적으로 본다면 이 두 가지 delivery guarantee를 고려해보게 될 것입니다. 메시지큐를 활용해서 Highly-available 한 서비스 구성을 위해 at-least-once 적용 시에는 그러지 않는 경우를 감안한 시스템 디자인 필요하고 at-most-once 적용시에는 그러지 않는 경우들을 감안한 디자인 적용이 필요합니다.

Delivery-guarantee들을 다른 방법으로 접근해보겠습니다. never, once, 그리고 more than once라는 세 가지 경우들에서 어느 경우들을 메시지큐에게 위임하고 어떤 경우는 서비스에서 직접 대비할지를 결정하는 방법입니다. 우아한 중계 서비스와 같이 각 메시지의 중요도가 높은 서비스에서 가장 치명적인 경우는never, 전달이 되지 않는 경우입니다. 이 부분을 메시지큐에게 위임하면 비즈니스가 자연스레 메시징 서비스에 의존하게 되기 때문입니다. 요구사항을 디테일하게 분석해서 어떤 delivery-guarantee를 적용할 수 있을지 고민해보는 것이 현명해 보입니다.
# Persistency (영속성) & Durability (내구성)
메시지큐의 Persistence 영속성
메시지큐 영속성의 단순한 의미는 메시지 처리하는 도중 서비스 failure 발생시, 메시지 보존여부를 의미합니다. (persistence means that when failure occurs during message processing, the message will still be there (where you found it the first time) to process again once the failure is resolved.)
메시지큐 Persistence의 대상은 메시징 플랫폼에 따라 호스트의 특정 폴더가 될 수 있고 데이터베이스가 될 수도 있고 로그파일이 될 수도 있습니다. 메시지를 보존하게 해주는 이런 훌륭한 기능의 트레이드오프는 성능입니다. 메시지를 어딘가에 보존하고 메모리의 메시지와 상태를 일치시키기 위해서 추가적인 I/O 가 발생하고 로직이 필요합니다. 그래서 persistency는 메시지 유실이 용인되는 정도에 따라 적용 여부를 결정하면 되겠습니다.
메시지큐의 Durability 내구성
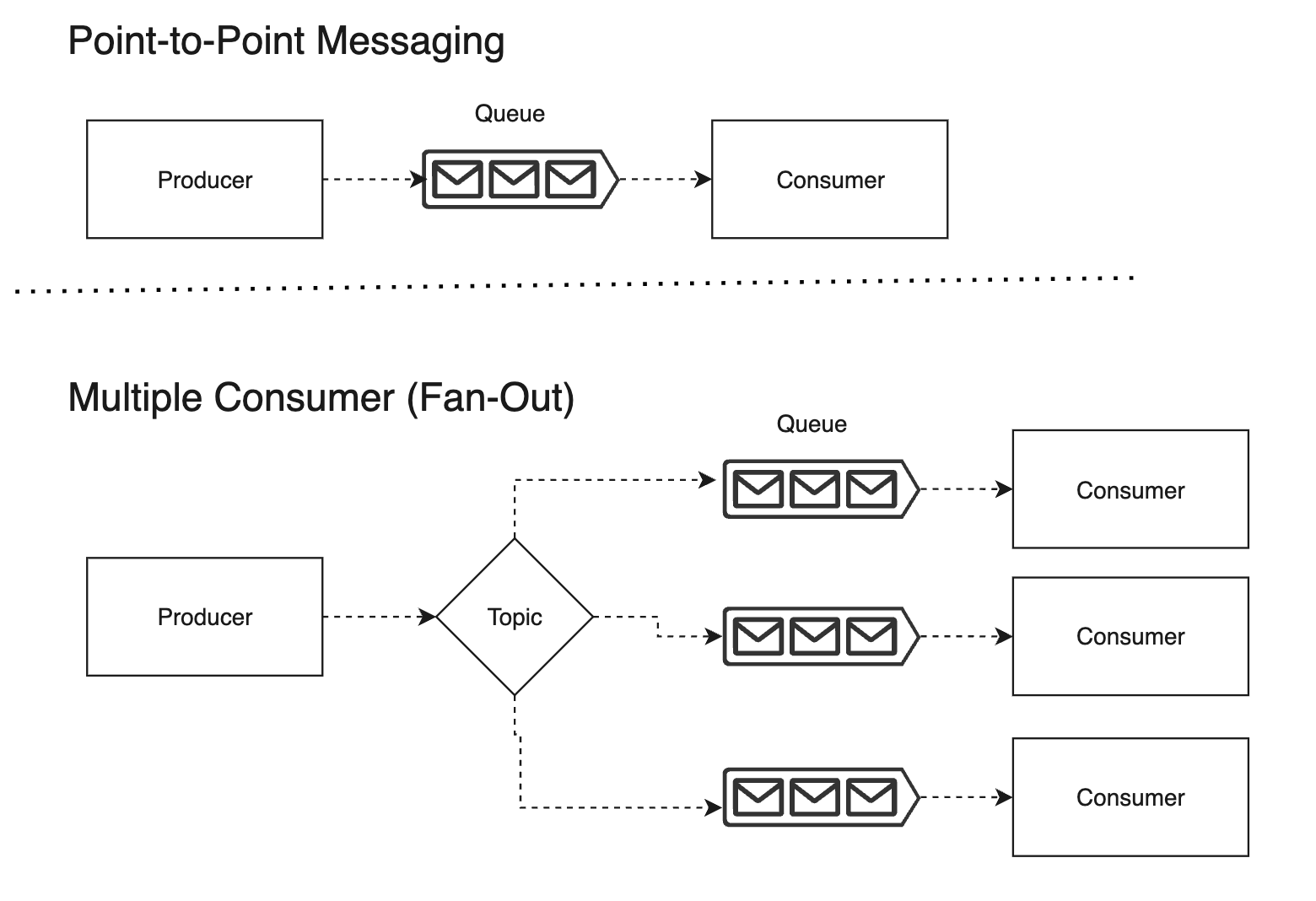
메시징 방법은 구독자수를 기준으로 point-to-point와 fan-out 방식이 존재합니다. producer와 consumer가 일대일로 연결되는 point-to-point 메시징에서는 큐가 직접적으로 사용됩니다. multiple-consumer(fan-out) 방식에서는 producer가 하나의 topic에 메시지를 발행하고 0개 이상의 queue들이 해당 topic을 구독하고 메시지를 consume(소비)합니다.
Durability, 정확히 말하면 durable subscription를 durability가 적용된 예시 시나리오를 통해 설명해보겠습니다.
- 여러 개의 queue들이 topic A에 durable subscription을 맺는다.
- publisher가 메시지 abc를 발행하는 시점에...
- 몇 개의 queue가 (failure와 같은 이슈들로 인해) offline 상태에 들어간다.
- topicA에 발행된 메시지 abc는 일시적으로는 온라인 상태인 큐들에게만 발행되고
- ***offline인 queue들이 online으로 돌아오면 메시지 abc가 전달된다(또는 가져간다)****
위에서 5번째 부분이 Durability가 적용된 부분입니다. Durability가 적용되지 않는다면 offline상태일 때 발행된 메시지 abc는 영원히 유실됩니다. Durability가 설정되지 않은 메시지 큐에서는 어떤 queue가 일시적으로 다운되고 복구됐을 경우 두 시점 사이에 발행되는 메시지들은 소비(consume)할 수가 없습니다. Durability 또한 메시지 유실이 용인되는 정도에 따라 적용 여부를 결정하면 되겠습니다.
# Ordering (순서)
메시지큐를 적용함에 있어서 서비스의 특성과 요구사항에 따라 메시징 서비스에서 제공하는 Ordering을 고려해볼 필요가 있습니다. 메시지가 [ A > B > C > D ] 순서대로 발행된다 하더라도 각 Consumer의 성능에 따라 [ A > C > B > D ] 순서대로 소비될 수 있기 때문인데요. 송금, 결제와 같은 처리 순서가 중요한 서비스에 메시지큐 적용 시 Ordering 기능을 제공하는지, 어느 범위까지 제공하는지, 어떻게 제공하는지를 상세히 살펴봐야 합니다. Ordering 또한 비용이 발생합니다. Ordering에 따른 성능 비용이 있을 수 있으며 Ordering에 따른 로직의 복잡도가 증가할 수도 있습니다.
# Filtering & Routing (필터링, 라우팅)
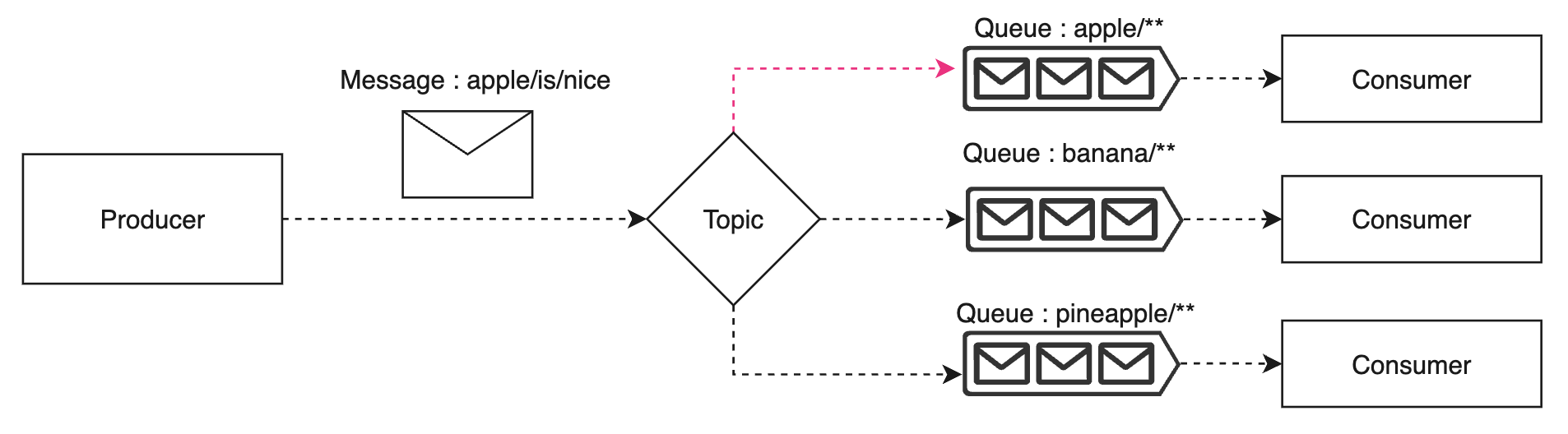
메시징에서 조건적인 publishing, 또는 조건적인 subscription 이 필요한 경우 필터링과 라우팅을 활용합니다. 메시지 헤더 또는 바디 value 따라 필터링을 해야 할 수도 있고 queue들을 계층구조로 구성해야 할 수도 있습니다.
다음은 메시지큐 적용 시 고려해볼 수 있는 여러 필터링/라우팅 옵션들을 살펴보겠습니다.
- 가벼운, Stateless 한 방식
- 큐 계층 기반
- topic 단위
- routing key, 또는 binding key
- Queue 단위
- Routing Key 또는 Binding Key 값
- Message Header
- Message Body
이외에도 찾아보시면 여러 메시지 라우팅/필터링 방식이 존재합니다.
마치며
과거에는 메시징하면 막연하게 -비동기 통신이다, 혹은 마이크로서비스는 메시징을 활용한다- 고 생각해온 기억이 나는군요. 지금까지 메시징의 본질적인 부분은 놓치고 이벤트 기반, MSA 등의 키워드에 대한 환상들만 안고 지내왔다는 생각이 듭니다.
-분산 시스템에서 메시징이 필요한 경우는 어떤 경우에 필요한지, 어떤 경우에 필요하지 않은지, 단점은 무엇인지, 단점을 상회하는 장점은 무엇인지, 단점을 보완하는 방법은 무엇인지- 에 대해서 고민하고 고민하기에 앞서 공부해보는 시간을 가지면서 메시징이 더 이상 silver-bullet 이 아닌 여러 트레이드오프를 가진 하나의 수단으로 보이기 시작합니다.
아래 참고자료로 기재해둔 두 가지 서적 "Software Architecture : The Hard Parts"와 "Microservices Patterns"에서 다루는 내용들이 그런 부분들입니다. 비동기 통신의 원리적인 부분부터 장단점, 필요한 이유, 문제점들과 해결방안들을 적절한 예시를 통해서 설명해주는 책들이니 필요시 참고하면 유익할 것으로 생각됩니다.
참고자료
"Software Architecture : The Hard Parts" by O'REILLEY
"Microservices Patterns" by Chris Richardson, MANNING
메시지큐의 영속성과 내구성에 대한 설명 : RedHat의 기술 블로그
'in-bob-we-trust' 카테고리의 다른 글
| 대용량 트래픽은 어떻게 테스트해야할까? 60만 RPM 테스트하기 (K6, AWS, EC2, 테스트, 성능테스트) (10) | 2022.06.09 |
|---|---|
| 테스트를 작성하고, 커버리지를 95% 이상 유지하며 익힌 것들 (Reactor, Spring WebFlux, JUnit, 단위테스트, 통합테스트, 추천인강) (0) | 2022.02.01 |
| 테스트를 작성하고, 커버리지를 95% 이상 유지하며 깨달은 것들 (테스트 철학, 전략, 노하우, Jacoco) (0) | 2022.01.31 |
| 서버 성능테스트 이야기 4 [ 성능개선 적용기 : StackTrace 최소화 ] (0) | 2022.01.28 |
| 서버 성능테스트 이야기 3 [ 성능개선 : JVM 메모리 영역 확장 ] (0) | 2022.01.28 |
분산 시스템, 마이크로서비스 아키텍처와 같은 개념들을 이야기하다 보면 빠지지 않는 것이 비동기 통신과 메시지 큐입니다. 대부분 메시지큐 기반 비동기 통신을 통해서 서비스간의 결합도를 낮춘다고 합니다. 우아한 중계서비스에서도 메시지큐를 활용한 비동기 통신을 고려하며 찾아본 내용들을 적어두었습니다.
Table of Contents
- 메시지 큐를 통해 해결하려는 문제는?
- 디커플링(decopuling), 서비스 간의 결합도 감소
- 관심사의 분리를 통한 처리시간 최적화
- 트래픽 완충제 역할
- 메시지 큐 활용시 해결해야 하는 문제는?
- 시스템 가용성 감소 Availability
- 시스템 복잡도 증가 Complexity
- 데이터 일관성 문제 Consistency
- Cheography-based Saga
- Orchestration-based Saga
- 메시지큐 적용을 위한 고려사항
- Delivery-Guarantee (전송, 전달 보증)
- exactly-once
- at-most -once 와 at-least-once
- Persistency (영속성) & Durability (내구성)
- 메시지큐의 Persistence 영속성
- 메시지큐의 Durability 내구성
- Ordering (순서)
- Filtering & Routing (필터링, 라우팅)
- Delivery-Guarantee (전송, 전달 보증)
- 마치며
- 참고자료
메시지 큐를 통해 해결하려는 문제는?
메시지 큐로 해결할 수 있는 문제들은 어떤 것들이 있을까요?
메시지 큐의 장점 세 가지 디커플링(decoupling), 비동기 (asynchronous), 트래픽 조절(peak-clipping)을 통해 살펴보겠습니다.
# 디커플링(decopuling), 서비스 간의 결합도 감소
Synchronous 한 통신 : 높은 결합도
위 다이어그램의 시스템은 Synchronous 해서 결합도가 높은 시스템의 예시입니다. 각 서비스간의 통신은 HTTP로 Synchronous 하게 통신하며 마치 여러 서버들로 구성된 하나의 거대한 메소드처럼 보이기도 합니다.
이러한 형태로 통신하는 상황에서는 애플리케이션의 버그, 간헐적인 네트워크 연결 실패, 데이터센터의 정전, 데이터 손실, 자연재해 등의 요인으로 인해 하나의 서비스라도 실패한다면 Synchronous 하게 통신되는 모든 서비스들이 실패하게 됩니다.
Asynchronous 한 통신 : 낮은 결합도
그에 반면 비동기 메시징으로 통신을 하면 서비스 간의 결합도를 감소시킬 수 있습니다. 메시징에서 서비스들은 메시지큐에 발행/구독 하는 것으로 본인의 책임을 다하기 때문입니다. 아키텍처 레벨에서 본다면 메시지큐를 통해 서비스간 책임의 경계를 지정할 수 있다고 생각할 수 있겠습니다.
# 비동기통신을 통한 성능 최적화 : Asynchronous
Synchronous 한 서비스들은 요청하거나 응답하는 과정에서 본인 관심사가 아닌 작업들까지 기다리게 되는 경우가 있어서 요청 처리시간이 길어지게 됩니다. 위 다이어그램을 예시로 살펴보겠습니다.
주문 서버는 새로 발생한 주문을 배달정보서비스까지만 전달하면 되는데, 배달정보서비스에서는 배달중계서비스까지 주문 정보를 전달하고, 또 배달중계서비스는 주문정보를 사장님 클라이언트까지 전달하고 있습니다.
이렇게 연쇄적으로 리턴으을 기다리다 보니 당연히 처리시간이 길어집니다. 병목이 전파되고, Latency는 증가하고 결과적으로는 고객만족도도 하락합니다. 너무 배고픈데 주문은 왜 이렇게 확인을 안 하는지....? 정말 필요한 부분만 동기로 두고 나머지는 비동기로 처리하면 어떻게 될까요?
Asynchronous 로 이루는 성능 최적화
비동기 메시징 적용에 대한 효과를 위의 예시를 통해 살펴보겠습니다. 적용 시 주문 서버에서 배달정보서비스로 주문을 전달하고, WAL의 역할을 수행하는 데이터베이스에 저장된 것까지만 확인하면 200 OK 응답을 받을 수 있습니다. 그 외 Relay-Service에게 전달, 사장님에게 전달 등의 작업들은 비동기로 진행되고 서비스의 관심사별로 작업들이 분리되며 서로의 시간을 절약하는 효과를 일으킵니다.
# 트래픽 완충제 역할 : Peak-Clipping
일시적으로 서버들이 감당 불가능한 규모의 트래픽이 발생하면 어떻게 될까요? Failure가 최선일까요? Scale Up? Scale Out?
AutoScaling 적용을 위해 고려해야 할 부분은 무엇이 잇을까요? 스케일하는 동안 사용자 요청들은 전부 Timeout 처리되어야 하나요? 서비스의 start-up time은? 서비스의 Warm-up 시간은? 스케일하기 위해 추적하는 지표는 몇 초 단위, 혹은 몇 밀리세컨드 단위의 빈도로 모니터링되는지? ASG가 생성하는 인스턴스는 얼마나 몇 ms 안에 RUNNING 상태에 들어가는지?
수평적, 수직적 스케일링은 모두 순간적(instantaneous)이지 못하기 때문에 트래픽이 밀리세컨드 단위로 폭발하는 서비스의 경우 단순 스케일링 방식은 해결방안이 될 수 없다는 것을 깨닫게 됩니다. 대신 메시지 큐로 해결 서비스의 앞에서 Buffer 처럼 트래픽을 받아들이고 consumer-side의 서비스들은 각자 최선을 다해 순차적으로 처리하는 접근 방법을 생각해볼 수 있습니다.
메시지 큐 활용 시 단점
이번에는 메시지큐를 활용할 경우 해결해야 하는 문제점에 대해서 살펴보겠습니다.
# 시스템 가용성 감소 Availability
서비스 간 비동기 통신으로 결합도를 낮추는데 availability도 감소한다? 는 말은 다소 모순되게 들릴 수도 있겠습니다. 메시지큐 도입시에는 메시지큐의 장애와 메시지의 유실까지 감안해서 서비스를 설계해야합니다.
# 시스템 복잡도 증가 Complexity
아래 메시지큐와 관련된 고려사항들 몇 가지들을 하나씩 살펴보겠습니다.
- Data Consistency (데이터 일관성***)
- Delivery-Guarantee (전송, 전달 보증)
- Persistency (영속성) & Durability (내구성)
- Ordering (순서)
- Filtering & Routing (필터링, 라우팅)
- Availability, Scalability, Performance (가용성, 확장성, 성능)
메시지큐를 도입하는 개발자의 머리속
메시지는 몇 번 전달(시도)할 수 있는지? 전달이 안 되는 경우에는?
중복처리는 어느 서비스에서, 어떻게 할지? 왜 그 서비스에서 해야 하는지?
데이터에 순서가 필요한지?
유실된 메시지는 어떻게 처리해야 하는지?유실이 안되게 하려면 어떤 방법이 있을지? 유실 가능한 정도는?
메시지 프로토콜은?
몇 ms안에 전달이 돼야 하는지?
특정 메시지큐를 적용 시 고려해야 하는 부분들은 무엇인지? 지원해주는 부분은 어떤 것들이 있는지?
또는 서비스에서 별도의 핸들링이 필요한 부분인지?
다른 대안은 무엇이 있는지?
# 데이터 일관성 문제 Consistency
비즈니스에서 가장 중요한 것은 무엇일까요? 데이터의 일관성입니다. 사용자가 쿠폰을 사용하면 쿠폰이 사용되어야하고 주문을 하면 주문이 전달되어야하고 그 모든 이벤트들 중심에 서 있(었던)는 것이 바로 데이터의 일관성, 트랜잭션과 ACID 입니다. 트랜잭션과 ACID 를 보장받는 시스템은 상대적으로 간결하고 개발하기도 매우 편합니다.
메시지큐가 많이 사용되는 분산시스템, 마이크로서비스 아키텍처의 경우 데이터 소스가 물리적으로 분리되어있는 경우가 많기 때문에 트랜잭션의 일관성을 유지하기 어렵습니다. 그래서 나타난 것이 BASE라는 키워드입니다. Basically Available, Soft State, Eventually Consistent로 구성된 BASE, 찾아보면 도움이 될 것으로 보입니다.
분산 시스템에서 데이터 일관성을 유지하는 방법으로는 분산 트랜잭션(Distributed Transaction)과 궁극적 일관성(eventual consistency)이 있습니다.
분산 트랜잭션은 all or nothing 으로 분산된 데이터소스들을 2-phase commit 방식의 트랜잭션으로 묶는 것이지만 성능적인 문제, 네트워크의 불안정성, 서비스간 높은 결합도 때문에 사용이 되지 않습니다.
궁극적 일관성 유지를 위한 방법으로는 Saga 패턴이 가장 많이 언급되는데요, Saga 패턴은 비동기 메시징을 활용하며 여러 서비스들의 로컬 트랜잭션을 순차적으로 실행되게 함으로써 데이터 일관성을 유지하는 방법입니다.
Saga 패턴은 다시 Choreography-based와 Orchestration-based 두 가지 방법으로 나뉩니다. 이 외에도 여러 Distributed Transaction 관리 전략이 있으며 참고를 위해 RedHat의 기술 블로그에서 소개하는 방법 몇 가지 링크 남겨둡니다.
Cheography-based Saga
Choreography-based saga의 경우 saga에 참여하는 각 서비스들이 서로 통신하면서 데이트의 일관성을 맞춰나가는 방법입니다.
Choreography 방식의 장점은 단순함과 낮은 결합도입니다. 각 서비스에서 필요한 이벤트를 발행하고 구독하기 때문에 단순하며 메시지큐를 활용해서 낮은 결합도(decoupled-ness)를 유지할 수 있습니다.
Choreography 방식의 단점은 서비스의 규모가 커질수록 장점들이 되려 치명적인 단점이 될 수 있다는 점입니다. Saga 참여자가 많아질수록 각 서비스 간의 contract(통신 계약)를 관리하기가 복잡해지며, 서로가 서로의 이벤트를 구독하는 순환 참조가 발생하고 디자인 품질이 떨어지게 됩니다. 게다가 여러 서비스가 직접적으로 Workflow 로직을 관리하다 보니 workflow와 서비스 간, 그리고 서비스와 서비스 간의 결합도가 높아지는 단점이 있습니다. 이러한 Choreography 방식의 단점들은 규모가 커질수록 N^2로 커져갑니다.
워크플로우가 정말 단순하거나 작은 규모의 Saga를 적용하는 경우, 또는 서비스 규모가 증가되지 않을 것이 예상되는 경우 Choreography-based saga 패턴을 고려해보는 것이 바람직해 보입니다.
Orchestration-based Saga
Orchestrated 방식에서는 사용자가 지정한 Orchestrator에 의해 centralized 한 방식으로 워크플로우가 실행됩니다.
Orchestration의 장점은 의존관계의 명확함, 낮은 결합도, 관심사의 분리, 그리고 비즈니스 로직의 간소화입니다. Orchestration에서 워크플로우 관련 로직들은 Orchestrator로 분리시켜 서비스 디펜던시가 위 다이어그램의 화살표처럼 단방향으로 명확합니다. 이런 명료한 서비스 구조는 빠르게 확장되는 서비스 확장에 있어 커다란 장점으로 적용됩니다. 그리고 워크플로우 관련 로직이 Orchestrator로 분리되어 서비스들은 상대적으로 가벼워지는 효과를 볼 수 있습니다.
Orchestration의 단점은 Orchestrator가 단일 실패 지점이 될 수 있다는 점입니다. 워크플로우의 흐름을 관리하기 때문에 failure 발생 시 서비스 자체가 불가능할 수 있습니다. Orchestration의 다른 단점은 비즈니스 로직이 Orchestrator에 집중될 리스크가 있다는 점입니다. Orchestration 적용 시 워크플로우 관리 로직만 Orchestrator 서비스에 추가되어야하는데 역할 분담을 철저히 하지 않는다면 많은 로직들이 Orchestrator로 쏠리고 나머지 서비스들은 Orchestrator 없이는 쓸모없어지는 양극화가 발생할 수 있습니다.
Orchestration-based Saga 패턴의 강점들은 서비스의 규모에 커질수록 매력적이기 때문에 상대적으로 많이 사용되는 추세입니다. 적용시 Orchestrator의 Failover를 탄탄히 구성하며 SPOF(단일실패지점)으로 전락하는 것을 예방하고 Orchestrator에 추가되는 로직들을 철저히 관리함으로써 최선의 결과를 낼 수 있을 것으로 보입니다.
# Delivery-Guarantee (전송,전달보증)
at-most-once delivery 최대 한번
at-least-once delivery 최소 한번
exactly-once delivery 정확히 한번 (effectively-once)
Delivery-Guarantee의 정의는 중요하지만 틀리게 설명할 가능성이 크기 때문에 제가 설명하지는 않겠습니다. 대신 키워드만 공유드리자면 delivery(배달, 전송)의 기준이 무엇인지, 메시지 publish 된다는 것의 기준은 정확히 무엇인지, subscriber에게 메시지가 전달됐다는 것의 기준은 무엇인지, duplicate writes, duplicate reads 등의 콘셉트들을 찾아보시는 것을 추천드립니다.
네, 그래서 delivery-guarantee에 대해서 이야기해보겠습니다. 메시징 서비스를 찾아볼 때는 보통 위 세 가지delivery guarantee를 많이 접하게 됩니다. 사실 모두가 바라는 것은 exactly-once, 정확히 한번 전달되는 guarantee입니다. 그렇다면 왜 at-most-once와 at-least-once가 존재하는 것일까요?
메시지가 생성되고 처리 되까지 delivery를 방해하는 많은 요인들이 존재합니다. 중복 또는 다중 쓰기, 입력 레코드 다시 읽기, partial failure, network failure, 패킷 유실, ack 유실 등의 여러 요인으로 exactly-once delivery 사실상 best-effort 라고 생각하는 것이 바람직하다고 볼 수 있겠습니다.
exactly-once를 감안하고 구성한 서비스의 구조는 정말 간결할 것이고 매력적이기 때문에 많은 메시징 서비스들이 exactly-once에 가까워지기 위해 끊임없이 노력하고 있는데요, 실제로 AWS SQS 나 Apache Kafka에서는 excatly-once delivery를 지원합니다.
*** Apache Kafka에서 제공하는 exactly-once는 Idempotent Producer, Transactions Across Partitions, Transactional Consumer 등의 기능/개념들을 활용합니다. 자세한 사항은 Confluent가 소개하는 Apache Kafka의 exactly-once delivery 블로그를 읽어보는 것을 추천드립니다.
결국 궁극적인 목표는 메시지의 전달입니다. 각 메시지의 중요도가 높아질수록 delivery-guarantee를 전제한 부분과 guarantee의 실패까지 고려한 설계가 요구됩니다.
exactly-once
exactly-once를 전제로 비동기 통신을 구성하는 경우 Apache Kafka, 또는 AWS SQS를 많이 사용하는 것으로 보입니다. 다른 메시징 서비스들은 exactly-once delivery 지원을 안 하거나 아직 premature 한 상태이기 때문에 서비스 단위의 failover가 복잡해지는 리스크가 있습니다. 예를 들어 Apache Kafka의 exactly-once를 활용한다면 비즈니스 로직들이 exactly-once에 의존하게 되겠지요.
at-most once와 at-least-once
exactly-once라는 개념을 다소 비관적으로 본다면 이 두 가지 delivery guarantee를 고려해보게 될 것입니다. 메시지큐를 활용해서 Highly-available 한 서비스 구성을 위해 at-least-once 적용 시에는 그러지 않는 경우를 감안한 시스템 디자인 필요하고 at-most-once 적용시에는 그러지 않는 경우들을 감안한 디자인 적용이 필요합니다.
Delivery-guarantee들을 다른 방법으로 접근해보겠습니다. never, once, 그리고 more than once라는 세 가지 경우들에서 어느 경우들을 메시지큐에게 위임하고 어떤 경우는 서비스에서 직접 대비할지를 결정하는 방법입니다. 우아한 중계 서비스와 같이 각 메시지의 중요도가 높은 서비스에서 가장 치명적인 경우는never, 전달이 되지 않는 경우입니다. 이 부분을 메시지큐에게 위임하면 비즈니스가 자연스레 메시징 서비스에 의존하게 되기 때문입니다. 요구사항을 디테일하게 분석해서 어떤 delivery-guarantee를 적용할 수 있을지 고민해보는 것이 현명해 보입니다.
# Persistency (영속성) & Durability (내구성)
메시지큐의 Persistence 영속성
메시지큐 영속성의 단순한 의미는 메시지 처리하는 도중 서비스 failure 발생시, 메시지 보존여부를 의미합니다. (persistence means that when failure occurs during message processing, the message will still be there (where you found it the first time) to process again once the failure is resolved.)
메시지큐 Persistence의 대상은 메시징 플랫폼에 따라 호스트의 특정 폴더가 될 수 있고 데이터베이스가 될 수도 있고 로그파일이 될 수도 있습니다. 메시지를 보존하게 해주는 이런 훌륭한 기능의 트레이드오프는 성능입니다. 메시지를 어딘가에 보존하고 메모리의 메시지와 상태를 일치시키기 위해서 추가적인 I/O 가 발생하고 로직이 필요합니다. 그래서 persistency는 메시지 유실이 용인되는 정도에 따라 적용 여부를 결정하면 되겠습니다.
메시지큐의 Durability 내구성
메시징 방법은 구독자수를 기준으로 point-to-point와 fan-out 방식이 존재합니다. producer와 consumer가 일대일로 연결되는 point-to-point 메시징에서는 큐가 직접적으로 사용됩니다. multiple-consumer(fan-out) 방식에서는 producer가 하나의 topic에 메시지를 발행하고 0개 이상의 queue들이 해당 topic을 구독하고 메시지를 consume(소비)합니다.
Durability, 정확히 말하면 durable subscription를 durability가 적용된 예시 시나리오를 통해 설명해보겠습니다.
- 여러 개의 queue들이 topic A에 durable subscription을 맺는다.
- publisher가 메시지 abc를 발행하는 시점에...
- 몇 개의 queue가 (failure와 같은 이슈들로 인해) offline 상태에 들어간다.
- topicA에 발행된 메시지 abc는 일시적으로는 온라인 상태인 큐들에게만 발행되고
- ***offline인 queue들이 online으로 돌아오면 메시지 abc가 전달된다(또는 가져간다)****
위에서 5번째 부분이 Durability가 적용된 부분입니다. Durability가 적용되지 않는다면 offline상태일 때 발행된 메시지 abc는 영원히 유실됩니다. Durability가 설정되지 않은 메시지 큐에서는 어떤 queue가 일시적으로 다운되고 복구됐을 경우 두 시점 사이에 발행되는 메시지들은 소비(consume)할 수가 없습니다. Durability 또한 메시지 유실이 용인되는 정도에 따라 적용 여부를 결정하면 되겠습니다.
# Ordering (순서)
메시지큐를 적용함에 있어서 서비스의 특성과 요구사항에 따라 메시징 서비스에서 제공하는 Ordering을 고려해볼 필요가 있습니다. 메시지가 [ A > B > C > D ] 순서대로 발행된다 하더라도 각 Consumer의 성능에 따라 [ A > C > B > D ] 순서대로 소비될 수 있기 때문인데요. 송금, 결제와 같은 처리 순서가 중요한 서비스에 메시지큐 적용 시 Ordering 기능을 제공하는지, 어느 범위까지 제공하는지, 어떻게 제공하는지를 상세히 살펴봐야 합니다. Ordering 또한 비용이 발생합니다. Ordering에 따른 성능 비용이 있을 수 있으며 Ordering에 따른 로직의 복잡도가 증가할 수도 있습니다.
# Filtering & Routing (필터링, 라우팅)
메시징에서 조건적인 publishing, 또는 조건적인 subscription 이 필요한 경우 필터링과 라우팅을 활용합니다. 메시지 헤더 또는 바디 value 따라 필터링을 해야 할 수도 있고 queue들을 계층구조로 구성해야 할 수도 있습니다.
다음은 메시지큐 적용 시 고려해볼 수 있는 여러 필터링/라우팅 옵션들을 살펴보겠습니다.
- 가벼운, Stateless 한 방식
- 큐 계층 기반
- topic 단위
- routing key, 또는 binding key
- Queue 단위
- Routing Key 또는 Binding Key 값
- Message Header
- Message Body
이외에도 찾아보시면 여러 메시지 라우팅/필터링 방식이 존재합니다.
마치며
과거에는 메시징하면 막연하게 -비동기 통신이다, 혹은 마이크로서비스는 메시징을 활용한다- 고 생각해온 기억이 나는군요. 지금까지 메시징의 본질적인 부분은 놓치고 이벤트 기반, MSA 등의 키워드에 대한 환상들만 안고 지내왔다는 생각이 듭니다.
-분산 시스템에서 메시징이 필요한 경우는 어떤 경우에 필요한지, 어떤 경우에 필요하지 않은지, 단점은 무엇인지, 단점을 상회하는 장점은 무엇인지, 단점을 보완하는 방법은 무엇인지- 에 대해서 고민하고 고민하기에 앞서 공부해보는 시간을 가지면서 메시징이 더 이상 silver-bullet 이 아닌 여러 트레이드오프를 가진 하나의 수단으로 보이기 시작합니다.
아래 참고자료로 기재해둔 두 가지 서적 "Software Architecture : The Hard Parts"와 "Microservices Patterns"에서 다루는 내용들이 그런 부분들입니다. 비동기 통신의 원리적인 부분부터 장단점, 필요한 이유, 문제점들과 해결방안들을 적절한 예시를 통해서 설명해주는 책들이니 필요시 참고하면 유익할 것으로 생각됩니다.
참고자료
"Software Architecture : The Hard Parts" by O'REILLEY
"Microservices Patterns" by Chris Richardson, MANNING
메시지큐의 영속성과 내구성에 대한 설명 : RedHat의 기술 블로그
'in-bob-we-trust' 카테고리의 다른 글
| 대용량 트래픽은 어떻게 테스트해야할까? 60만 RPM 테스트하기 (K6, AWS, EC2, 테스트, 성능테스트) (10) | 2022.06.09 |
|---|---|
| 테스트를 작성하고, 커버리지를 95% 이상 유지하며 익힌 것들 (Reactor, Spring WebFlux, JUnit, 단위테스트, 통합테스트, 추천인강) (0) | 2022.02.01 |
| 테스트를 작성하고, 커버리지를 95% 이상 유지하며 깨달은 것들 (테스트 철학, 전략, 노하우, Jacoco) (0) | 2022.01.31 |
| 서버 성능테스트 이야기 4 [ 성능개선 적용기 : StackTrace 최소화 ] (0) | 2022.01.28 |
| 서버 성능테스트 이야기 3 [ 성능개선 : JVM 메모리 영역 확장 ] (0) | 2022.01.28 |