
Contents
- 이번 이야기
- Definitions
- 테스트 Overview
- 1,000 RPS 테스트 : 설명
- 1,000 RPS 테스트 : 결과
- 2,000 RPS 테스트 : 설명
- 2,000 RPS 테스트 : 결과
- 점검의 시간 : What Application Load Balancer is doing for us
- 로드밸런싱
- Health Check
- Scaling
- Service Discovery & Service Registration
- L7(Layer 7) Load Balancing
- 점검의 시간 : Scalability (확장성) 보완하기
- 10,000 RPS 테스트 : 설명
- Computing 서비스 구조
- Monitoring 서비스 구조
- 10,000 RPS 테스트 : 결과 1
- 10,000 RPS 테스트 : 결과 2
- 예상되는 개선 포인트들
- 마치며
이번 이야기
최근 Info-Service 서버에 대한 성능 테스트를 진행했습니다. 테스트를 통해 2 vCPU, 4 GiB mem 기준 info-service 서버는 적정 Throuhgput 1000 RPS를 가지고 있는 것을 확인할 수 있었습니다.
서버의 적정 Throughput을 계산하고 나면 이런 의문들이 떠오릅니다.
서버 1대당 1000 RPS면...
서버 2대는 2천 RPS인가?
서버 10대는 1만 RPS를 핸들링할 수 있을까?
서버 10대가 모여 1만 RPS를 안정적인 상태를 유지하고 계속 핸들링할 수 있을까?
이번 블로그에서 위 질문들에 대한 답을 찾는 과정의 최대한 많은 것을 설명해보려고 합니다.
내용 중 저와 다르게 생각하는 부분들은 항상 환영합니다. 댓글로 남겨주시면 정성껏 답변하겠습니다.

Definitions
우선 RPS와 RPM 사전 정의하겠습니다.
- RPS : Requests per second (1초 동안 요청 수)
- RPM : Requests per minute (1분 동안 발생하는 요청 수)
- Info-Service : 배달정보서비스의 모듈명으로 이번 테스트의 메인
- Relay-Service : 배달중계 서비스의 모듈명으로 Info-Service가 필요로 하는 기능을 가지고 있음.
테스트 Overview
"어떤 테스트를 진행하는가"에 대해 설명하겠습니다. 테스트 시나리오는 현재 진행 중인 우아한 중계 서비스의 핵심 로직을 그대로 담아냈습니다. 시나리오는 다른 배달의민족 서비스에서 신규 주문의 중계 요청(POST /api/delivery)을 받음으로써 시작되고 실제 중계 서비스의 유저 플로우를 순서대로 실행합니다. 시나리오 1회 실행은 "신규 주문 중계 요청"부터 "배달완료"까지 총 5개의 요청을 전송하고 응답받는 것을 의미합니다.

테스트 스크립트는 K6를 활용했으며 이유는 다음과 같습니다.
- Test as Code : 테스트 프레임워크 선정에 중요한 부분으로 Scriptability over UI를 고려했습니다. 스크립팅 가능시 반복적인 테스트를 작성하거나 버전 관리하기에 용이합니다. 필요시 자동화도 상대적으로 편리하게 할 수 있습니다. K6는 테스트의 모든 대부분을 코드로 작성 가능합니다.
- Ease-of-use : K6는 팀원이 익숙하며 러닝 커브가 낮은 자바스크립트로 작성합니다.
- Lightweight : K6는 가볍습니다. 테스트 툴들의 가상 유저는 보통 스레드와 1대 1 매핑시킵니다. NGrinder, Jmeter 등 자바 툴들은 스레드 별 최소 1MB의 메모리가 발생하지만 K6의 런타임은 Go 언어로 Go의 스레드는 개당 100kb를 넘지 않습니다. 참고자료
1,000 RPS 테스트 : 설명
1차 테스트에서는 지난 성능 테스트 결과의 복습 차원에서 진행하겠습니다. 1대의 Info-Service 서버가 예상한 대로 동작하는지, 그리고 예상한 대로 상태를 유지하는지 확인해보겠습니다. 테스트를 위한 전체 서비스 구조는 다음과 같습니다.

- 트래픽을 발생시키는 K6 테스트는 AWS EC2 서버에서 1000명의 가상 유저를 생성하고 AWS Application Load Balancer로 초당 1000~1100 개의 요청을 전송합니다.
- 첫 2분 동안은 0 RPS부터 1100 RPS까지 상승하며 이후 10분 동안 1000~1100 RPS의 트래픽을 발생시킵니다.
- Load Balancer는 트래픽 전체 1000 RPS를 info-service-01 서버 1 대로 라우팅 합니다.
- Info-Service-01는 테스트 시나리오에 따라 Application Load Balancer 뒤에 있는 Relay-Service로 요청을 전송하거나, 또는 Relay-Service와 공유하는 MongoDB로 쿼리를 전송합니다.
1,000 RPS 테스트 : 결과
테스트 결과는 지난 성능 테스트 결과와 크게 다르지 않습니다. 서버는 1000~1100 RPS를 안정적으로 처리하고 평균 요청 처리시간은 10ms 수준을 유지하고 있습니다. 요청 처리시간이 짧은 이유는 위 다이어그램의 모든 서비스가 하나의 AWS availbility zone에서 동작하고 있기 때문은 아닐까 싶습니다. CPU 사용량 또한 70~80% 구간을 유지하며 예상한 수준에 머무르고 있습니다.

현재 구성된 모든 서비스의 CPU 사용량을 분석해보겠습니다. 아래는 CPU 사용량 지표를 나타낸 AWS CloudWatch의 대시보드입니다. 위 지표와 마찬가지로 Info-service는 CPU 사용량 70%, K6 테스트 트래픽을 발생시키는 서버 프로그램은 CPU 사용량 10~30% 나머지는 CPU 사용량 10% 이하로 유지되고 있습니다.

현재 구성된 모든 서비스의 메모리 사용량 %를 확인해봅니다. 아래 메모리 사용량 % 그래프를 보면 Info-Service는 지난 테스트 결과와 유사하게 호스트 전체 메모리의 30%선에 머무르고 있습니다.

Info-Service 서버 1대는 1,000 RPS의 트래픽을 검증했던 대로 핸들링하는 것이 확인됩니다. 이제 2대로 스케일-아웃해보겠습니다.
2,000 RPS 테스트 : 설명

2차 테스트에서는 info-service 서버를 2대로 스케일 아웃하고 2배의 트래픽, 2,000 RPS을 발생시켜보겠습니다. 테스트를 위한 전체 서비스 구조는 다음과 같습니다.
- 트래픽을 발생시키는 K6 테스트는 AWS EC2 서버에서 2000명의 가상 유저를 생성하고 AWS Application Load Balancer로 초당 2000~2200 건의 HTTP Request를 전송합니다.
- 첫 2분 동안 0 RPS부터 2200 RPS까지 상승하며 이후 10분 동안 2000~2200 RPS 구간을 유지합니다.
- Load Balancer가 전체 발생 트래픽의 50%는 info-service-01 서버로 분배하고 나머지 50%의 트래픽은 info-service-02 서버로 분배합니다.
- Info-Service 그룹은 테스트 시나리오에 맞게 데이터베이스로 쿼리를 전송하거나 또 다른 Application Load Balancer 뒤에 있는 Relay-Service로 요청을 전송합니다.
이번 테스트에서 달라진 점은 다음 두가지 입니다.
- Info-Service 서버가 두 대로 스케일 아웃
- Info-Service 앞단에 존재하는 Application Load balancer가 실제 로드밸런싱 역할을 수행한다는 점
예상하는 결과는 1,000 RPS 테스트의 결과가 Info-Service-01과 Info-Service-02에 유사하게 나타나는 것입니다.
일단 로드밸런싱이 예상한 대로 동작하는지 간단한 실험을 통해 확인해보겠습니다. 아래 소스코드는 이번 테스트를 위해 제가 사전에 미리 구현해놓은, IP 주소를 리턴하는 GET 메서드입니다. GET ${baseUrl}/ip로HTTP Request를 전송하면 호스트 머신의 주소를 반환합니다.
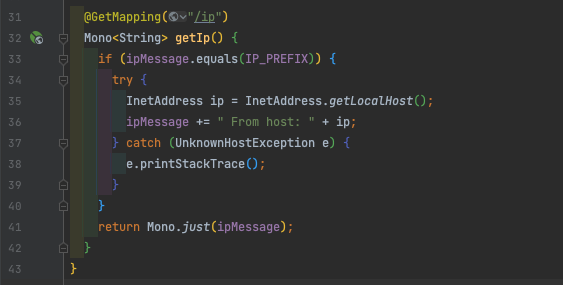

제가 사전에 실행시켜둔 Info-Service 서버 2대가 있습니다. Info-Service 그룹의 Application Load Balancer로 수차례 HTTP GET${baseUrl}/ip 요청을 전송해보겠습니다.

예상한 대로 반환되는 두 가지 IP 주소가 약 50% 비율로 나누어 반환되는 것을 확인할 수 있습니다. 상당히 읽기 불편해 보이므로 빨간색 사각형으로 표시해두었습니다.
스케일 아웃한 서버 2대의 로드밸런싱이 계획한 대로 이루어지는 것이 확인됩니다. 그렇다면 이제 테스트를 진행해보겠습니다.
2,000 RPS 테스트 : 결과
이번 테스트는 2분 동안 트래픽을 0 RPS부터 2200 RPS까지 증가시켰으며 이후 10분 동안 2200 RPS를 유지했습니다. 아래는 K6 테스트의 Summary입니다. 지금까지의 결과와 크게 다르지 않으며 모든 Request를 성공적으로 처리했으니 다음 지표로 넘어가겠습니다.

아래는 테스트 진행 시간 동안 발생한 서비스별 CPU 사용량 데이터를 살펴보겠습니다. 데이터는 각 서비스의 호스트 머신에 설치된 CloudWatch Agent를 통해 수집되었으며 AWS CloudWatch 쿼리 및 시각화되었습니다.

최상단 브라운과 바이올렛 라인 차트는 Info-Service-01 서버와 Info-Service-02 서버의 CPU 사용량을 나타냅니다. 두 차트 모두 예상되는 패턴을 그리며 정상 작동하는 것이 확인됩니다.
다음은 Memory 사용량 % 을 나타내는 차트입니다.

모든 Info-Service 서버가 40% 미만의 메모리 점유율을 기록하고 있으며 변동폭도 예상했던 패턴을 그리고 있습니다.
Info-Service 서버 그룹의 지표도 확인해볼 필요가 있습니다. 첫 번째 Info-Service 서버의 지표를 살펴보겠습니다.

서버의 Public DNS는 Red 사각형으로 표시해두어 "아래 두 개의 차트 모음은 다른 서버의 지표를 나타낸다"를 강조해봅니다.
위 지표들의 인스턴스 Public DNS 네임은 ec2-15-164-103-214.... 입니다.
Rate(Requests Per Second)는 의도한 1000~1100 RPS 수준을 유지하고 있습니다.
Duration, 평균 응답 시간은 10ms로 테스트에 함정인가 싶을 정도로 양호한 결과가 나타납니다. 이전과 달리 이번 테스트에서는 K6 테스트 서버를 포함한 모든 서버가 물리적으로 같은 AZ(Availability Zone)에서 동작하며 Latency가 최소화되었다는 점, 그리고 서비스 로직 자체가 상당히 가볍다는 점들이 작용된 것으로 보입니다.
JVM Heap, 사이즈 변동을 살펴보면 일정한 패턴으로 GC가 발생하는 것이 보입니다.
CPU 사용량도 최근 측정한 "2 vCPU 4 GiB Memory에서 동작하는 Info-Service 서버"의 적정 CPU 사용량을 유지하고 있는 것이 확인됩니다.
두 번째 Info-Service 서버의 지표를 살펴보겠습니다.

인스턴스의 Public DNS는 ec2-3-37-88-87.... 입니다.
Rate(Requests Per Second)는 첫 번째 Info-Service 서버와 거의 동일하게 의도한 1000~1100 RPS 수준을 유지하는 것이 확인됩니다.
Duration, 평균 응답 시간은 첫 번째 Info-Service 서버와 약간의 차이가 있지만 유사도가 상당히 높습니다.
JVM Heap 또한 예상한 행동 패턴을 그리고 있습니다.
CPU Usage 활용량도 최근 측정한 "2 vCPU에서 동작하는 Info-Service 서버"의 적정 CPU 사용량을 아슬아슬하게 유지하고 있는 것이 확인됩니다.
이번 2,000 RPS 테스트 결과 분석의 마지막으로 Info-Service 서버 Fleet의 Application Load Balancer에 1분 간격으로 발생한 트래픽을 확인해보며 테스트의 정상작동을 검증해보겠습니다. 아래는 1분 동안 처리한 요청 수를 나타내는 그래프입니다. 4xx , 5xx response는 포함하지 않습니다.

테스트 시간 동안 12만 RPM, 즉 서버 한대당 적정 Throughput 1,000 req/s 만큼의 트래픽을 핸들링하는 것을 확인할 수 있습니다.
다음 순서는 Info-Service (t3.medium) 서버 10대로 스케일 아웃해서 테스트 트래픽 60만 RPM, 1만 requests per second를 핸들링하는 테스트입니다. 다음 테스트로 바로 넘어가기 전에 지금까지 진행한 테스트들의 여러 부분들을 살펴보고, 다음 테스트에 대한 계획도 세워보는 점검의 시간을 가져보도록 하겠습니다.
잠시 : Application Load Balancer 이 제공하는 것

현재 적용 중인 AWS Application Load Balancer는 무엇인지, 그리고 테스트를 실행하는 동안 AWS ALB에게 암묵적으로 위임한 기능들에 대해 생각해보겠습니다.
아래는 AWS 공식문서에서 발췌한 핵심 포인트들입니다. 1번부터 5번 항목까지 ALB가 암묵적으로 어떠한 기능들을 수행해주고 있는지, 그리고 ALB가 없는 경우의 상황을 생각해보는 시간을 가져보겠습니다.
1. Elastic Load Balancer는 EC2 인스턴스, 컨테이너, IP 주소 등 여러 대상에 걸쳐 수신되는 트래픽을 자동으로 분산합니다.
2. 등록된 대상의 상태를 모니터링하면서 상태가 양호한 대상으로만 트래픽을 라우팅 합니다.
3. Elastic Load Balancing은 수신 트래픽이 변경됨에 따라 로드 밸런서를 확장합니다.
4. 지정한 프로토콜과 포트 번호를 사용하여 EC2 인스턴스 같은 하나 이상의 등록된 대상으로 요청을 라우팅 합니다.
5. 개방형 시스템 간 상호 연결(OSI) 모델의 7번째 계층인 애플리케이션 계층에서 작동합니다.
출처 : https://docs.aws.amazon.com/ko_kr/elasticloadbalancing/latest/application/introduction.html
1. 로드밸런싱
1. Elastic Load Balancer는 EC2 인스턴스, 컨테이너, IP 주소 등 여러 대상에 걸쳐 수신되는 트래픽을 자동으로 분산합니다.

AWS에서 설명하는 AWS-fully-managed(AWS 완전 관리형) 서비스인 ALB의 주요 기능입니다.
테스트에서 저는 HTTP Request들의 목적지를 ALB의 퍼블릭 엔드포인트로 설정했고, ALB는 수신한 요청들을 사전에 정의된 규칙에 따라 각 Info-Service 서버에 적절히 분배했습니다. 2000 RPS 테스트 결과로 가늠할 수 있듯이 라우팅 알고리즘에 ALB의 default 값인 round-robin 방식이 적용되어 있으며 서버 2대에 동등하게 분배된 트래픽을 확인할 수 있습니다.
2. Health Check
2. 등록된 대상의 상태를 모니터링하면서 상태가 양호한 대상으로만 트래픽을 라우팅 합니다.

지금까지의 테스트는 해피 케이스이기 때문에 인지하지 못했을 수도 있지만 ALB는 동작하는 동안 등록된 서버들의 HealthCheck 진행하고 있습니다. ALB는 사전에 프로토콜, 포트, URI 등으로 정의된 엔드포인트와 규칙들을 통해 서버의 HeartBeat을 확인하고 있었습니다.
여기서 염두해야 할 점은 HealthCheck는 ALB가 대신해주지만 엔드포인트는 사용자가 서버에서 구현해야 한다는 것입니다. 저 또한 사전에 미리 구현해두었기 때문에, 문제없이 진행할 수 있었습니다.
프로젝트 Health Check Endpoint

이번 테스트를 위해 구현한 GET ${baseUrl}으로 작성한 Health Check 엔드포인트. HealthCheck는 HTTP StatusCode로 표현되고 해석되는 것이 효율적이다라고 생각했기 때문에 최대한 단순하게 구현했으며. 원한다면 Spring Actuator 를 활용해서 더욱 상세한 정보를 얻을 수도 있습니다. /actuator/health 엔드포인트를 활용할 수도 있습니다.
3. Scaling
3. "Elastic Load Balancing은 수신 트래픽이 변경됨에 따라 로드 밸런서를 확장합니다."
ALB가 없다면 로드밸런싱을 위해 어떤 작업들을 진행해야 할까요?
- 직접 하드웨어를 공수하거나 AWS EC2와 같은 IaaS(Infrastructure as a Service)들을 활용해서 자원을 확보한다.
- Nginx와 같은 로드밸런싱 툴을 선택하거나 직접 구현한다.
- 실행한다.
- 트래픽에 맞추어 확장(Scale out/up)과 축소(Scale in/down)를 반복한다.
- 장애를 기다린다.
우리가 암묵적으로 넘어갈 수 있는, AWS Application Load Balancer와 같은 AWS의 fully-managed 서비스들 활용하면서 잊고 있는 부분들입니다. 요구되는 서비스/기능들이 항상 AWS가 제공하는 서비스들과 정확히 일치하는 것은 아니기 때문에, "염두에 두면 활용 가능한 지식들이다"라고 생각해봅니다.
추가로 AWS-fully-managed 서비스들은 AWS에서 전적으로 관리해주지만 그런 서비스들도 내부적으로 서버가 있고 하드웨어가 있기 때문에 트래픽의 규모, 변동폭이 정말로 클 것으로 예상되는 부분들은 Throttle 과 TimeOut이 발생할 수도 있으니 사전에 미리 찾아보고, 테스트해보는 시간이 필요합니다. 예를 들어 AWS Lambda Function의 Concurrency Limit은 Region 별 1,000이며 증가를 위해서는 ㄷAWS Support로 요청을 해야 합니다.
4. Service Discovery & Service Registration
4. "지정한 프로토콜과 포트 번호를 사용하여 EC2 인스턴스 같은 하나 이상의 등록된 대상으로 요청을 라우팅 합니다."

제가 테스트를 위해 Application Load Balancer에 무엇을 등록했을까요? 서버 IP 주소목록? Target Group?
저는 Info Service 서버의 TargetGroup을 ALB의 port 80 라우팅 대상으로 등록해두었습니다. 이후 서버 초기화 시 TargetGroup에 추가했고, 이후 ALB는 Target Group과 협력해서 등록된 서버 주소들을 확인하고 로드밸런싱을 진행합니다. 이 과정에서 포인트 들는 Service Discovery와 Service Registration입니다.
Service Registration(또는 Service Registry)는 마이크로 서비스 디자인 패턴으로 서비스들의 접속 정보들을 데이터베이스처럼 관리하겠을 의미 합니다. 이번 케이스에서는 TargetGroup이 Service Registry 되겠습니다. TargetGroup은 AWS-fully-managed 서비스이므로 별도 관리입니다. 클라우드 플랫폼에 독립적인 서비스를 지향한다면 스프링의 경우 Spring Eureka를 예로 들 수 있겠습니다.
여기서 Service Discovery는 동적으로 변화하는 서비스들과 통신하기 위한 행위라고 이야기할 수 있습니다. Service Discovery 에는 Client-Side Service Discovery와 Server-Side Service Discovery 패턴이 있습니다. 이 두 가지 패턴은 Nginx 공식 홈페이지에 자세히 설명되어있습니다. 이번 케이스에서 클라이언트(K6 가상 유저)들은 ALB의 Public DNS 주소 하나로 모든 요청을 전송하고 있습니다. Info-Service 서버들의 주소 확인부터 라우팅까지 모두 ALB가 담당하고 있기 때문에 server-side service discovery 패턴으로 생각해 볼 수 있습니다.
5. L7(Layer 7) Load Balancing
5. "Application Load Balancer는 개방형 시스템 간 상호 연결(OSI) 모델의 7번째 계층인 애플리케이션 계층에서 작동합니다."
여기서 Layer 7 은 OSI 네트워크 7 계층의 Layer 레벨을 의미합니다. HTTP/S 은 Layer 7에서 작동하는 De Facto Standard 프로토콜이고 ALB는 HTTP/S 프로토콜을 지원합니다. (위 이미지) HTTP/S 에서 동작하기 때문에 Http Header, Http 메서드 기반 라우팅 룰을 설정할 수 있습니다.
AWS에서 L7 외에 Layer-4 (Network Load Balancer), Layer-3 (Gateway Laod Balancer) 로드밸런싱도 있습니다. 레이어가 낮아질 수 핸들링하는 패킷이 줄어들고 라우팅 룰의 디테일함이 떨어지지만 그만큼 처리량은 증가합니다. 아마 인터넷에 찾아보면 AWS의 여러 LoadBalancer의 성능 벤치 마크한 블로그들을 어렵지 않게 찾을 수 있을 것이라 생각합니다.
더 자세한 내용은 AWS Elastic Load Balancer 제품 비교 페이지에서 확인가 능합니다.
점검의 시간 : Scalability (확장성) 보완하기

지금까지 Info-Service 서버를 (2대 까지) 수동으로 스케일-아웃한 방법은 이렇습니다.
- AWS EC2 Instance를 초기화
- ALB의 라우팅 대상인 Target Group에 인스턴스 IP 주소 등록
- 인스턴스에 AWS CloudWatch Agent 설정 및 실행
- 초기화한 인스턴스의 IP를 Prometheus 서버에 모니터링 타깃으로 등록 (GET /actuator/prometheus)
지금까지 위 프로세스를 정확히 2번 거치고 2,000 RPS를 테스트할 수 있었습니다. 위 작업을 2번, 3번까지 반복하는 것은 괜찮지만 이제 다음 테스트를 위해 10번을 반복해야 합니다. 만약 무료 치킨 선착순 이벤트를 대비한다면 100번을 반복해야 될 수도 있는 상황입니다. 반복되는 서버 초기화 작업을 최적화 수 있을까요? 키워드를 Auto Scaling으로 설정하겠습니다.
AWS에서 서버를 Auto Scaling 할 수 있는 방법 몇 가지가 있습니다. 서버를 Docker 이미지로 빌드해서 컨테이너 단위로 스케일 아웃할 수도 있으며, EC2 인스턴스 단위로 스케일 아웃 할 수도 있습니다. 이번 블로그에서는 두 번째 방법을 활용하겠습니다. AWS EC2 Auto Scaling에서는 사용자가 사전에 정의한 Launch Configuration(또는 Launch Template)과 조건들을 바탕으로 애플리케이션을 자동으로 Scale Out(Up) 하고 Scale In(Down) 합니다. 이후 진행되는 테스트에서는 위 4단계의 수동 스케일 아웃하는 과정을 자동화해보겠습니다.
10,000 RPS 테스트 : 설명
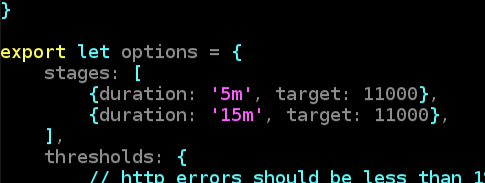
이번 블로그 포스트의 마지막 성능 테스트입니다. 위 K6 테스트 스크립트를 보면 첫 5분 동안은 0 RPS부터 11,000 RPS까지 증가시키고 이후 11,000 RPS를 15분 동안 유지하게 됩니다.
이번 테스트에서는 Info-Service 서버 Fleet와 Relay-Service 서버 Fleet을 각 10대, 5대로 스케일 아웃합니다. 해당 규모로 핸들링 가능할 것으로 예상되는 테스트 트래픽 10,000 RPS(600,000 RPM)을 발생시킵니다. 테스트를 진행하면서, 구성된 서비스 각 컴포넌트들이 어떻게 동작하는지, 6만 RPM에서 보지 못한, 60만 RPM에서 비로소 발생하는 문제점들이 있는지, 현재 서비스를 어떻게 개선할 수 있는지 등을 알아갈 예정입니다.
우선 서비스 구조를 Computing과 Monitoring 파트로 나눠서 살펴보겠습니다. 참고로 점차 디자인 욕심도 생기고, 10대로 ScaleOut 하는 과정에서는 이전 테스트들과 달라진 부분들이 여럿 있습니다.
Computing 서비스 구조

- K6와 MongoDB의 호스트 vCPU와 Memory를 2배로 증가시켰습니다. K6와 MongoDB는 2000 RPS 테스트에서 CPU 사용량이 최대 각 40%, 20%까지 증가했기 때문에 사용량의 변동을 40*5, 20*5로 계산해보고 내린 결정입니다.
- 1000 RPS 테스트와 2000 RPS에 활용하지 않았던 AWS의 Auto Scaling 기능을 적용했습니다. Auto Scaling Group을 생성하기 위해서 원하는 상태(yum install pkgs....)의 서버 인스턴스를 만들고 Amazon Machine Image(AMI), 그리고 AMI를 활용한 Launch Template (인스턴스 초기화 템플릿)을 작성했습니다. (해야만 합니다.)
- Info-Service 서버와 Relay-Service 서버들은 과거 성능 테스트 & 적정 Throughput 검증 과정에서 사용한 t3.medium EC2 Instance를 그대로 적용했습니다.
Monitoring 서비스 구조

- 서버의 JVM 데이터 확보를 Spring Actuator + Micrometer Registry
- JVM 모니터링 데이터에 접근할 수 있는 서버 엔드포인트 Http GET /actuator/prometheus입니다.
- 모든 Info-Service 서버 Fleet과 Relay-Service 서버 Fleet에 적용되는 부분입니다.
- Spring Boot Actuator 내부의 Micrometer Registry의 기능으로 간단한 디펜던시 추가와 단순한 Spring 스타일의 Configuration으로 구성 가능합니다.
- 서버의 JVM 데이터 수집을 위한 Prometheus
- 일정 주기 단위로 등록된 모든 Target 서버들의 지표를 polling 방식으로 수집합니다.
- Prometheus가 스케일 아웃하며 생성되는 인스턴스의 접속 정보를 어떻게 가져오게 설정하는지 궁금하시다면 ec2_sd_configs라는 키워드를 통해 탐구할 수 있습니다. 해당 키워드는 내부적으로 AWS의 ec2 describe-instances 커맨드 라인 API를 활용해서 ec2 인스턴스 메타데이터를 가져와서 파싱 하는 기능들을 제공합니다.
- JVM 모니터링 데이터를 2 vCPU, 4 GiB Memory로 구성된 t3.medium EC2 Instance Type입니다.
- 서버의 JVM 데이터 시각화를 위한 Grafana
- 2번 Prometheus 서버가 수집하는 데이터들을 시각화하는 툴입니다.
- 테스트 외의 운영 작업을 최소화하기 위해 Grafana Cloud 서비스의 Free-Tier 플랜을 사용했습니다.
- 서버의 시스템 정보를 Push 하는 AWS CloudWatch Agent
- Amazon Machine Image와 user-data를 활용해 사전에 설치해둔 CloudWatch Agent는 설정된 주기 단위로 AWS CloudWatch Metrics로 시스템 모니터링 데이터를 Push 합니다.
- 모든 Info-Service 서버 Fleet과 Relay-Service 서버 Fleet에 적용되는 부분입니다.
- 이번 테스트에서는 Memory 점유율과 CPU 사용량을 관찰했습니다.
- 서버의 시스템 정보를 수집하고 쿼리 가능한 AWS CloudWatch Metrics
- 서버 Fleet의 CloudWatch Agent들이 push 하는 데이터들이 쌓이는 AWS의 서비스입니다.
- AWS Console UI와 CloudWatch search expression syntax를 활용해서 AWS에서 활용되는 여러 리소스들의 지표를 확인할 수 있으며 이번 10,000 RPS 테스트에서는 서버 CPU 사용량, Memory 점유율, ALB Request Count 등을 수집할 예정입니다.
- 서버의 시스템 데이터 시각화를 위한 CloudWatch DashBoard
- 5번의 CloudWatch Metrics에서 여러 쿼리들을 조합한 후 모니터링을 위한 대시보드를 구성할 수 있습니다.
- Line, Bar, Pie 등 일반적인 차트는 모두 제공합니다.
- 여기서는 Time-Series 데이터들 위주로 다루기 때문에 Line Chart를 적용하겠습니다.
- Prometheus와 CloudWatch는 호환이 가능합니다.
- 혹시라도 Prometheus, CloudWatch Agent 등을 이 블로그에서 처음 접해보시는 분들이 있을까 싶어 기재해둡니다.
- Prometheus와 CloudWatch Agent는 설정을 통해 CloudWatch 대시보드에서 JVM 데이터와 시스템 데이터 모두 수집/조회/분석/시각화가 가능하며 반대로 Prometheus에서도 가능합니다.
- 여기서 JVM 데이터와 시스템 데이터를 분리해서 모니터링하는 이유는 통합 모니터링까지 구성하는 Operational Overhead라 판단되어 통합 작업을 진행하지 않았습니다.
서버 구성 후 캡처한 AWS EC2 콘솔입니다. Info-Service Fleet 10대, Relay-Service Fleet 5대, K6 1대, MongoDB 1대, Prometheus 1대 총 18대의 크고 작은 서버들로 구성되는 서비스입니다. 이보다 더 큰 규모의 리소스들을 핸들링하는 엔지니어들이 존경스러워지는 시점입니다.

이제 10,000 RPS, 600,000 RPM 테스트를 실행해보겠습니다.
10,000 RPS 테스트 : 결과 1
아래는 K6 테스트 스크립트를 실행한 콘솔 아웃풋입니다.

10,000 RPS (1만 가상 유저) 부근부터 에러가 발생합니다. K6가 테스트 데이터를 push 하는 InfluxDB에서 발생하는 문제로 보입니다. 찾아보니 로그에 적힌 내용 일맥상통하게 InfluxDB 가 HTTP로 한 번에 전송받을 수 있는 데이터 사이즈의 한계가 있으며 max-body-size 또는 max-payload-size를 최댓값으로 설정하는 솔루션이 있어서 설정 정보를 변경해보겠습니다.
추가로 CloudWatch 시스템 모니터링 지표들을 살펴보겠습니다.

이상 현상이 관찰됩니다. K6, Prometheus, MongoDB 서버들의 시스템 지표들을 모아서 대시보드에 구성한 Utility Service 관련 그래프입니다. 좌측은 CPU 사용량, 우측은 Memory 점유율을 나타냅니다.
K6(green) 서버의 CPU 사용량과 Memory 점유율이 실제 캡처 후 수집된 데이터에서도 이미 CPU, Memory 각 90%, 70% 이상을 사용하고 있기 때문에 과부하로 단정하겠습니다.
K6 데이터에 가려져있기는 하지만 MongoDB(orange) 서버의 CPU 사용량 또한 과부하를 나타내고 있습니다. 메모리는 10% 대로 양호한, 문제로 여기기 힘든 상태입니다. 테스트 시나리오가 Write-heavy 하기 때문에 find Query는 많이 캐싱해두지 않은 것이 이유로 보입니다. MongoDB서버도 CPU 과부하로 단정하겠습니다.

우선 K6와 MongoDB 서버 인스턴스 사양을 두배로 늘리겠습니다. CPU와 Memory 모두 두배로 증가시키겠습니다.
K6는 c5.2 xlarge(8 vCPU & 16 GiB Mem)에서 c5.4 xlarge (16 vCPU & 32 GiB Mem)로 전환하겠습니다.
MongoDB는 t3a.2 xlarge (8 vCPU & 32 GiB Mem)에서 i3.4 xlarge로 전환하겠습니다. i3 인스턴스 패밀리는 SSD로 구성하는 높은 Random I/O 와 I/O 성능을 가지고 있습니다. (AWS에서 그렇다고 합니다.) 실제로 제가 인스턴스 타입별 MongoDB Community Edition 성능 벤치마크를 찾아본 결과 t3a 패밀리에서 i3로 전환하는 것은 개선된 단순 CPU와 메모리 확장 이상의 성능 개선 효과를 가져올 것으로 보입니다.
이렇게 K6 서버와 MongoDB 서버의 성능은 개선되지만 MongoDB의 인스턴스 타입을 변경하면 다른 문제가 발생합니다. EC2 Instance는 새로 생성하거나 stop/start 할 경우 새로운 IP 주소가 할당됩니다.
그렇다면 총 15대 info-service + relay-service 서버의 데이터베이스 커넥션은 어떻게 업데이트해야 할까요? 이 부분은 마지막에 다루거나 별도로 다루겠습니다. 다루지 않을 경우를 대비해 미리 키워드를 기록해두겠습니다. AWS Systems Manager, AWS Run Command입니다.
10,000 RPS 테스트 : 결과 2
테스트를 실행합니다. 앞으로 당분간 이 정도 규모의 테스트를 진행할 여건이 안될 것이므로 여러 지표들을 자세히 담아보려 해 보겠습니다.

K6입니다. 테스트 결과입니다.
- http_req_duration (요청+응답 소요시간) Min 1.59ms, percentile(95) 764ms, Max 4s 인근까지 증가하는 것이 확인됩니다. 비록 Outlier 일지라도 서비스 퀄리티의 변동폭이 큰 부분은 개선이 필요합니다.
- checks (시나리오 성공 여부) 다행히 테스트 시나리오는 한 번도 실패하지 않았습니다. 최근 성능 개선 과정에서 500ms로 설정해두었다가 삭제한 MongoDB Query TimeoutException 덕분입니다. 서비스 Delay가 오류는 아닐지언정 서비스 품질 확보에 긍정적인 요소는 아니므로 이 부분도 개선이 필요합니다.
- http_reqs 10분 동안 811만 2150 건의 요청을 전송했습니다. 6170 RPS는 목표한 성능 대비 60% 수준입니다.
사전에 K6 Test Summary 기준 테스트 성공/실패 여부를 정하지는 않았지만 10,000 RPS와는 거리가 멀기 때문에 우선 실패를 염두에 두고 계속 살펴보겠습니다..
우선 CloudWatch Metric의 Info-Service 서버 Fleet의 CPU 사용량을 이번 10,000 RPS(상)와 1,000(하)로 나누어 비교해보겠습니다.

테스트에서 첫 몇 분간은 0부터 목표 RPS까지 증가 후 목표 RPS를 유지하기 때문에 1,000 RPS 테스트 그래프와 같이 테이블탑 형식의 차트가 나와야 합니다. 하지만 10,000 RPS 테스트에서는 peak까지 상승 후 전체적으로 하락하는 것을 확인할 수 있습니다. 메모리가 과부하가 아니라면 Relay-Service와 Info-Service 관련 문제인 것으로 보입니다. Info-Service 서버 Fleet의 메모리 점유율 변동을 확인해보겠습니다.


메모리 사용량 % 은 10,000 RPS 테스트와, 1,000 RPS 테스트 결과 모두에서 30% 선에서 머무르고 있는 것을 보면 JVM 모니터링 지표에서도 문제가 없을 것으로 보입니다. CloudWatch Metric 지표들도 한번 살펴보겠습니다.




Relay-Service 서버 Fleet, Utility 서버 Fleet CPU와 메모리 사용량 모두 과부하의 흔적은 보이지 않습니다. 네트워크 또는 ALB의 문제로 접근해 볼 필요가 있어 보입니다. 우선 ALB에는 목표한 트래픽이 발생했는지 살펴보겠습니다. 아래는 Info-Service 서버 Fleet 앞 단에서 동작하며 Public Endpoint의 역할도 수행하는 AWS ALB의 1분 당 처리된 요청 수(Request Counts per Minute)를 나타냅니다.

시작 시점부터 첫 5분간은 37만 RPM부터 최대 74만 RPM까지 처리하지만 이후 다시 피크의 절반 수준인 37만 RPS까지 하락하게 됩니다. JVM 모니터링 지표를 살펴보기 전 잠시 "10,000 RPS은 달성했으나 60만 RPM 은 달성하지 못했다."는 생각을 해볼 수 있습니다.
다음으로 Grafana Cloud에 구성해 놓은 Info-Service 서버의 JVM 모니터링 지표를 살펴보겠습니다. 서버 10대의 지표라 이미지가 세로로 많아 보기 불편할 수 있습니다.






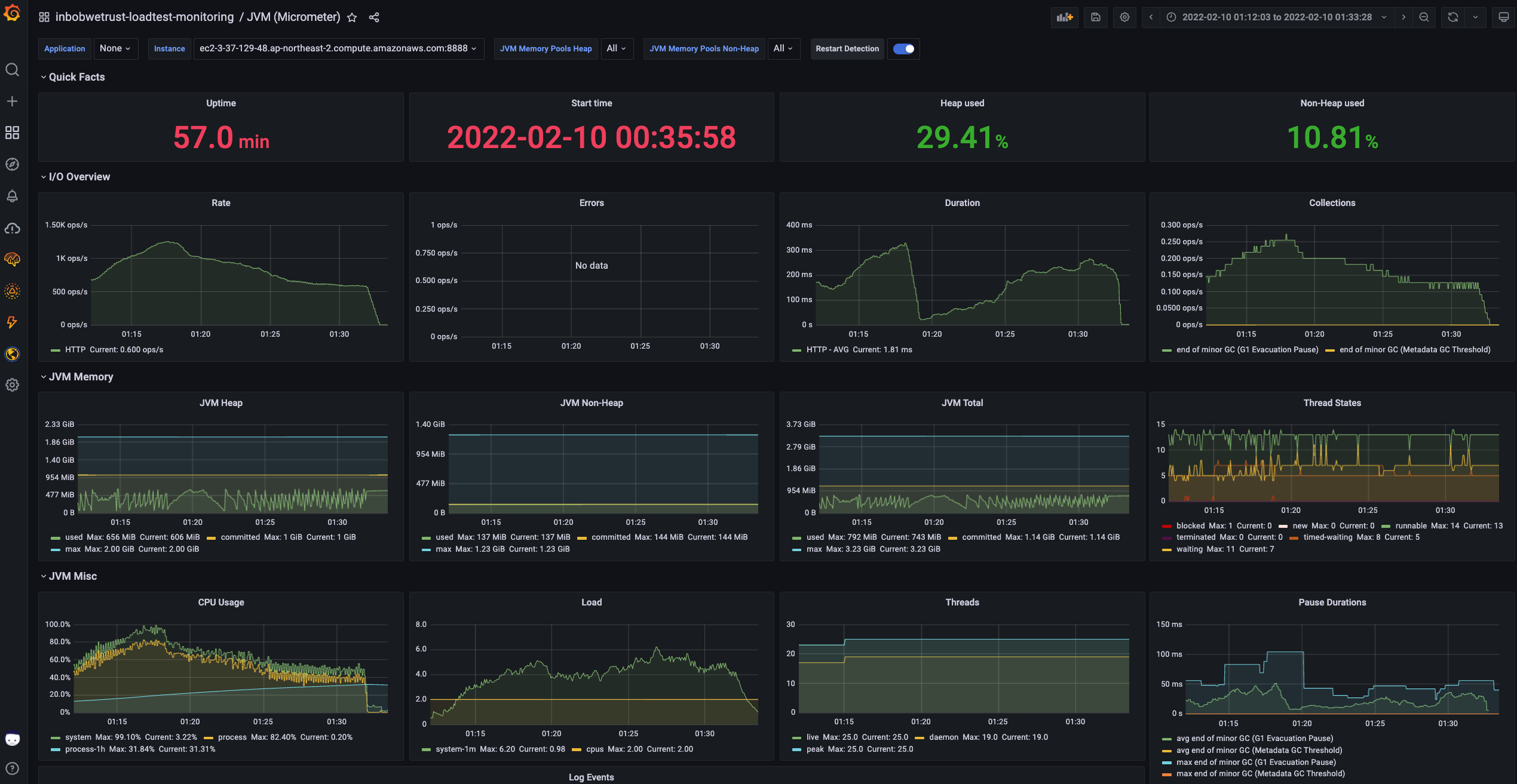



모든 서버의 대부분의 지표들은 위에서 본 ALB의 requestCounts과 유사한 패턴을 나타내고 있습니다. 여기서 가장 눈에 띄는 부분은 Duration(평균 요청 처리시간)입니다. Duration은 74만 RPM을 처리하는 구간까지 점점 증가(느려짐)하고 이후 큰 급격히 빨라지는(그래프의 Drop) 현상이 관찰됩니다. 어딘가에서 Throttle이 발생하고 스케일 한 것처럼 보이는군요. 이후 Duration 은 왜 RPS와 함께 증가했으며, 왜 이후 급격히 감소했고, 왜 RPS와 반대로 움직이기 시작했는지, 원인은 무엇인지 등을 찾아보겠습니다.
다음은 Relay-Service 서버 5대의 JVM 지표입니다.





Relay-Service 서버 fleet 지표에서 관찰할 수 있는 부분은 GC로 인한 Pause시간이 20ms에서 40ms, 그리고 20ms에서 60ms까지 증가하는 부분 드링 있다는 점, 그리고 Duration이 RPS와 반비례하며 움직이는 것이 눈에 들어옵니다. 블로킹 상태에 빠지는 없어 보입니다.
지금까지 내용들을 바탕으로 테스트 결과를 정의하겠습니다. 테스트 결과 Info-Service Fleet 10대로 스케일 아웃한 서비스는 목표 처리량 1만 RPS, 60만 RPM을 지나 74만 RPM까지 도달했지만 유지하지 못하고 37만 RPM 까지 하락하며 실패했습니다.
테스트 결과가 실패이니 개선이 필요한 부분들을 살펴보겠습니다.
예상되는 개선 포인트들
실패한 테스트를 성공시키기 위한 개선, 또는 점검 가능한 포인트들 몇 가지 생각해보겠습니다.
1. EC2 인스턴스의 Packet Throughput vs Byte Throughput
찾아보니 저와 유사한 문제를 겪은 사례들을 찾을 수 있었고 네트워크의 관점에서 접근한 사례가 있었습니다. EC2의 모니터링 지표를 보면 네트워크의 처리량을 패킷단위와 바이트 단위로 구분해서 표시되어있습니다. 이 점을 깊게 파고들어 AWS 네트워크의 Guaranteed와 Best-Effort 성능을 벤치마킹한 블로그를 참고해볼 만한 가치가 있어 보입니다.
2. EC2 인스턴스의 Bursting

AWS 에는 Bursting이라는 개념이 있습니다. 변동폭이 큰 트래픽을 핸들링하는 웹 서비스들을 위한 개념으로 낮으면서 저렴한 기본 성능을 유지하며 이후 추가적인 CPU 사용량을 크레딧의 형태로 소비하며 급증하는 트래픽에 대응할 수 있게 합니다. 모든 서버들의 Burst 크레딧을 살펴보고 74만 RPM 도달 전과 후 시점에 큰 폭으로 변동하는 서버를 찾을 수 있다면 해당 서버를 Scale Up 해보는 것도 한 방법으로 보입니다.
3. ALB의 Throttle
ALB에서도 Throttle이 발생할 수 있을까요? AWS의 Application Load Balancer 또한 어딘가에서 동작하는 서비스입니다. 그러므로 설정에 따라 성능에도 차이가 발생할 수 있습니다. 검색해보면 설정에 따라 변화하는 ALB의 성능을 확인할 수 있습니다. 어쩌면 ALB를 살펴보는 것도 유의미해 보입니다.
마치며
최근 서버의 성능 테스트와 적정 Throughput 확인을 진행한 내용들을 바탕으로 서버를 2대, 10대로 스케일 아웃하고 각 2000 RPS, 10,000 RPS의 트래픽을 테스트해봤습니다. 스케일 아웃 과정에서 AWS ALB의 로드밸런싱 기능을 들려다 봤으며, 2대까지는 문제가 없어 보였지만 10대의 서버와 10배의 트래픽을 핸들링하는 과정에서는 문제가 발생했고, 발생한 문제를 개선하는 방안들을 생각해봤습니다.
예상했던 대로 2대의 서버를 가지고 2,000 RPS의 트래픽을 핸들링하는 경우와 10대의 서버를 가지고 10,000 RPS의 트래픽을 핸들링하는 경우는 다른 문제들이 나타나기 시작하는 것이 확인됩니다. 아쉽지만 이번 블로그에 할애하는 시간은 한정되어있으므로 추가 진행은 잠정 중단입니다.
'in-bob-we-trust' 카테고리의 다른 글
| 메시지큐를 활용한 비동기 통신에 대해서 알아보자 (0) | 2022.04.01 |
|---|---|
| 테스트를 작성하고, 커버리지를 95% 이상 유지하며 익힌 것들 (Reactor, Spring WebFlux, JUnit, 단위테스트, 통합테스트, 추천인강) (0) | 2022.02.01 |
| 테스트를 작성하고, 커버리지를 95% 이상 유지하며 깨달은 것들 (테스트 철학, 전략, 노하우, Jacoco) (0) | 2022.01.31 |
| 서버 성능테스트 이야기 4 [ 성능개선 적용기 : StackTrace 최소화 ] (0) | 2022.01.28 |
| 서버 성능테스트 이야기 3 [ 성능개선 : JVM 메모리 영역 확장 ] (0) | 2022.01.28 |