Pulsar의 차별점 ("Apache Pulsar in Action" 챕터 1.5)
본 포스트는 “Manning Publications”에서 출판하고 현재 StreamNative 에서 무료 배포 중인 책 “Apache Pulsar in Action”의 내용을 정리한 내용입니다. 본 포스트는 비상업적이며 학습 목적으로 작성되었습니다. 전문적인 내용은 반드시 원서를 참조하시기 바랍니다. 모든 저작권은 해당 출판사와 저자에게 있습니다.
링크:
1. 원서(출판사) : https://www.manning.com/books/apache-pulsar-in-action
2. 원서(배포본) : https://streamnative.io/ebooks/get-your-free-copy-of-mannings-apache-pulsar-in-action

1.5 Why do I need Pulsar?
메시징이나 스트리밍 데이터 애플리케이션을 처음 개발하는 경우, Apache Pulsar는 메시징 인프라의 핵심 구성 요소로 고려할 만한 가치가 있습니다. 그럼에도 불구하고, 세상에는 소프트웨어 커뮤니티에 오랜기간 동안 활용되온 많은 기술 옵션이 존재한다는 점을 인지하고 있어야합니다.이 섹션에서는 Apache Pulsar가 다른 시스템보다 더 부각되는 몇 가지 시나리오를 소개하고, 기존 시스템에 대해 존재하는 일반적인 오해를 풀어내고, 이러한 시스템의 사용자들이 직면하는 몇 가지 도전 과제를 지적하려고 합니다.
도입 주기에서는 종종 사용자 커뮤니티 전체에서 다양한 이유로 확립된 기술에 대한 여러 오해가 유지됩니다. 여러분의 시스템 아키텍처 핵심 기술을 교체해야 한다는 것을 본인과 다른 사람들에게 설득하는 것은 대부분 어려운 일입니다. 기존의 데이터베이스 시스템은 끊임없이 증가하는 우리의 데이터 규모에 부합하는 수준으로 스케일할 수 없다는 것을 뒤늦게나마 알게되며 우리는 Hadoop과 같은 프레임워크로 데이터를 저장하고 처리하는 방식을 고려해야 했습니다. 기존의 데이터 웨어하우스에서 Hive, Tez, Impala와 같은 Hadoop 기반 SQL 엔진으로 비즈니스 분석 플랫폼을 전환한 후에야, 이러한 도구들이 1초 미만의 응답시간에 익숙한 용자들에게는 불충분하다는 것을 깨달았습니다. 이로 인해 Apache Spark는 빅 데이터 처리를 위한 기술 선택으로 빠르게 채택되었습니다.
이 두 가지 최근 기술을 통해 강조하고 싶은 것은, 현 상황에 대한 우리의 안정감으로 인해 우리의 핵심 아키텍처 시스템 내에 숨겨져 있는 문제를 알아채지 못한다는 점을 인지시키고 RabbitMQ와 Kafka와 같은 이 분야의 깊게 자리잡은 기술들이 사실 핵심적인 아키텍처 결함을 가지고 있기 때문에 우리는 메시징 시스템에 대한 접근 방식을 재고해야 한다는 방향을 제시하려는 것입니다. Yahoo!에서 Apache Pulsar를 개발한 팀 또한 쉽게 당시 존재하던 솔루션 중 하나를 채택하기로 결정했을 수 있겠지만, 신중한 검토 끝에 그들은 기존의 monolithic 기술에서는 제공할 수 없는 기능을 제공하는 메시징 플랫폼이 필요하다고 결정했습니다. 이에 대해서는 다음 섹션에서 논의하겠습니다.
1.5.1 Guaranteed message delivery
이전 장에서 이미 다룬 플랫폼 내의 데이터 영속성 메커니즘 덕분에 Pulsar는 애플리케이션을 위한 메시지 전달을 보장합니다. 메시지가 Pulsar 브로커에 성공적으로 도달하면, 해당 메시지는 모든 토픽 소비자에게 전달됩니다.
이러한 보장을 제공하려면, ack되지 않은 메시지들이 모든 컨슈머에게 전달되고 ack될 때까지 내구성(durable) 있는 방식으로 저장되어야 합니다. 이러한 메시징 모드는 보통 영속성 메시징(persistent messaging)이라고 불립니다. Pulsar에서는 모든 메시지가 설정 가능한 수만큼의 사본이 디스크에 저장되고 동기화됩니다.
기본적으로, Pulsar 메시지 브로커는 메시지의 수신이 acknowledge하기 전까지 스토리지 계층에 디스크에 영속되도록 합니다. 이 메시지들은 ack될 때까지 Pulsar의 무한대로 확장 가능한 스토리지 계층에 보관되어, 메시지 전달을 보장합니다.
1.5.2 Infinite scalability
Pulsar의 확장성을 더 잘 이해하기 위해, 일반적인 Pulsar 환경을 살펴보겠습니다. Figure 1.21에서 볼 수 있듯이, Pulsar 클러스터는 두 개의 계층으로 구성됩니다: 클라이언트 요청을 처리하는 브로커 집합으로 구성된 무상태(stateless) 서비스 계층과, 메시지를 영속화를 수행하는 북키퍼 집합으로 구성된 상태성(stateful) 영속 계층입니다.
메시지 저장소와 메시지를 서비스하는 계층을 분리하는 아키텍처 패턴은, 이 두 서비스를 함께 위치시키는 전통적인 메시징 시스템과 큰 차이가 있습니다. 이러한 분리된(decoupled) 접근 방식은 확장성 측면에서 여러 가지 장점을 가지고 있습니다. 시작으로, 브로커를 무상태(stateless) 만들면 클라이언트 애플리케이션의 요구에 맞게 브로커의 수를 동적으로 늘리거나 줄일 수 있습니다.
SEAMLESS CLUSTER EXPANSION
저장 계층에 추가된 모든 북키퍼는 브로커에 의해 자동으로 발견되며(automatically discovered), 브로커는 즉시 메시지 저장에 이들을 활용하기 시작합니다. 이는 Kafka와는 다른점으로, Kafka는 새로 추가된 브로커에게 들어오는 메시지를 분산시키기 위해 토픽을 재파티셔닝하는 것이 필요합니다.
UNBOUNDED TOPIC PARTITION STORAGE
Kafka와 달리, 토픽 파티션의 용량은 가장 작은 노드의 용량에 의해 제한되지 않습니다. 대신, 토픽 파티션은 스토리지 계층의 총 용량까지 확장될 수 있으며, 이 역시나 단순히 북키퍼를 추가함으로써 확장될 수 있습니다. 이전에 논의했듯이, Kafka 내의 파티션은 저장공간의 크기에 대한 여러 제한이 있지만, Pulsar에는 그런 제한이 적용되지 않습니다.
INSTANT SCALING WITHOUT DATA REBALANCING
메시지 서비스와 저장이 두 개의 계층으로 분리되어 있기 때문에, 토픽 파티션의 브로커 간 이동은 거의 즉시(instantly) 이동시킬 수 있으며, 이 작업은 데이터 리밸런싱의 필요없이(한 노드에서 다른 노드로 데이터를 복사하는 것) 없이 이루어집니다. 이 특성은 클러스터 확장 및 브로커와 북키퍼 장애에 대한 빠른 실패에 대한 대응 등 많은 것에 핵심이 됩니다.
1.5.3 Resilient to failure
Pulsar의 분리된(decoupled) 아키텍처는 시스템 내에 단일 실패 지점이 없음을 보장함으로써 더욱 강력한 회복 탄력성을 제공합니다. 서비스 계층과 저장 계층을 분리함으로써, Pulsar는 시스템 내의 실패가 미치는 영향을 제한하고 복구 과정을 매우 매끄럽게 만듭니다.
SEAMLESS BROKER FAILURE RECOVERY
브로커는 Apache Pulsar에서 무상태 서비스 계층을 형성합니다. 서비스 계층이 무상태인 이유는 브로커가 실제로 메시지 데이터를 로컬에 저장하지 않기 때문입니다. 이로 인해 Pulsar는 브로커의 실패에 대해 내구성을 가집니다. 브로커가 다운되었음을 감지하면, Pulsar는 즉시 프로듀서와 컨슈머를 다른 브로커로 전송할 수 있습니다. 데이터는 별도의 계층에 보관되므로, Kafka와 같이 데이터를 다시 복사할 필요가 없습니다. Pulsar는 데이터를 다시 복사할 필요가 없기 때문에, 복구는 토픽의 데이터 가용성을 희생없이 즉시 이루어집니다.
반면에, Kafka는 모든 클라이언트 요청을 최신 데이터를 항상 가지고 있는 리더 복제본(replica)로 전달합니다. 또한 리더는 실패 시 필요한 데이터를 다른 노드에서 사용 가능하도록 들어오는 데이터를 복제 그룹의 다른 팔로워로 전파하는 책임이 있습니다. 그러나 리더와 복제본 사이의 내재되어 있는 지연 때문에, 데이터가 복사되기 전에 데이터가 손실될 수 있습니다.
SEAMLESS BOOKIE FAILURE RECOVERY
Pulsar가 사용하는 상태성 있는 영속성 계층은 이전에 언급했듯이 세그먼트 중심의 스토리지를 제공하는 Apache BookKeeper 북키퍼로 구성됩니다. 메시지가 Pulsar에 게시되면, 데이터는 ack되기 전에 모든 N 복제본의 디스크에 영속화됩니다. 이 설계는 데이터가 여러 노드에 보존되며 데이터가 손실되기 전까지 N-1 개의 노드의 failure를 견딜 수 있음을 보장합니다.
또한, Pulsar의 저장 계층은 자가 복구(self-healing) 기능을 가지고 있어서 특정 세그먼트의 복제가 불충분해지거나 노드 또는 디스크 실패가 발생하면, Apache BookKeeper는 이를 자동으로 감지하고 백그라운드에서 복제에 대한 복구를 스케줄링합니다. Apache BookKeeper의 복제 복구는 세그먼트 단위의 many-to-many 빠른 복구로, Kafka에서 필요로하는 전체 토픽 파티션 복사 훨씬 더 세밀한 단위입니다.
1.5.4 Support for millions of topics
다음 시나리오를 생각해보겠습니다. customer 라는 엔티티를 중심으로 애플리케이션을 모델링하고, 고객별 하나의 토픽을 두는 상황입니다. 각 엔티티(고객)에 대해 다양한 이벤트가 게시됩니다; 고객 엔티티 생성, 주문, 결제, 반품, 주소 변경 등의 이벤트입니다.
이벤트들을 단일 토픽에 배치함으로써, 이벤트가 올바른 시간 순서대로 처리되는 것이 보장되며 고객 계정의 정확한 상태를 빠르게 파악할 수 있습니다. 비즈니스가 성장함에 따라 수백만 개의 토픽을 지원해야 할 필요가 발생하지만 전통적인 메시징 시스템에서는 이런 요구사항을 해결 할 수 없습니다. 많은 토픽을 가지는 것은 end-to-end 지연 시간의 증가, 파일 디스크립터(file descriptor), 메모리 오버헤드, 실패 후 복구 등의 시간에 큰 비용이 따릅니다.
경험상 Kafka에서는 만족스러운 지연 시간을 유지하기 위해 토픽 파티션의 총 수를 수백 개 단위로 유지해야 하는 것이 좋습니다. 이 제한을 피하기 위해 Kafka 기반 애플리케이션을 어떻게 재구성해야 하는지에 대한 여러 가이드까지 존재합니다. 토픽을 어떻게 구조화할지에 대한 애플리케이션 설계가 플랫폼 제한에 영향을 받지 않기를 원한다면, Pulsar를 고려해야 합니다.
Pulsar는 최대 280만 개의 토픽을 지원하면서 일관된 성능을 제공할 수 있는 능력을 가지고 있습니다. 토픽 수를 확장하는 핵심은 저장 계층에서 기본 데이터가 어떻게 구성되는지에 있습니다. Kafka와 같은 전통적인 메시징 시스템에서처럼 토픽 데이터가 전용 파일이나 디렉토리에 저장되면, 토픽 수가 증가함에 따라 디스크 전체에 I/O가 흩어져서 디스크 스래싱이 발생하고, 이로 인해 매우 낮은 처리량이 발생하며, 처리량에 제한이 발생합니다. 이를 방 방지하기 위해, Apache Pulsar에서는 다른 토픽의 메시지들이 집계되고, 정렬되고, 큰 파일에 저장되며, 이후에는 인덱싱됩니다. 이 접근 방식은 토픽 수가 증가함에 따라 성능 문제를 초래하는 작은 파일의 확장을 제한합니다.
1.5.5 Geo-replication and active failover
Apache Pulsar는 단일 Pulsar 클러스터 내 동기식 지리적 복제(synchronous geo-replication)와 여러 클러스터 간 비동기식 지리적 복제를(asynchronous geo-replication) 모두 지원하는 메시징 시스템입니다. 2015년부터 Yahoo!의 10개 이상의 데이터 센터에 전세계적으로 배포되어 왔으며, Yahoo! 메일과 파이낸스와 같은 핵심 서비스를 위해 10x10 메시 복제를 완벽하게 지원합니다.
지리적 복제는 엔터프라이즈 시스템에 재해 복구 기능을 제공하기 위해 사용되는 일반적인 방법으로, 데이터의 복사본을 서로 다른 지리적 위치에 분산시킵니다. 이는 자연 재해와 같은 예측할 수 없는 상황에서도 데이터와 그에 의존하는 시스템이 계속 작동할 수 있도록 보장합니다. 다양한 데이터 시스템에서 사용되는 지리적 복제 메커니즘은 동기식 또는 비동기식으로 분류될 수 있습니다. Apache Pulsar는 소수의 설정만으로 비동기식 지리적 복제를 쉽게 활성화할 수 있습니다.
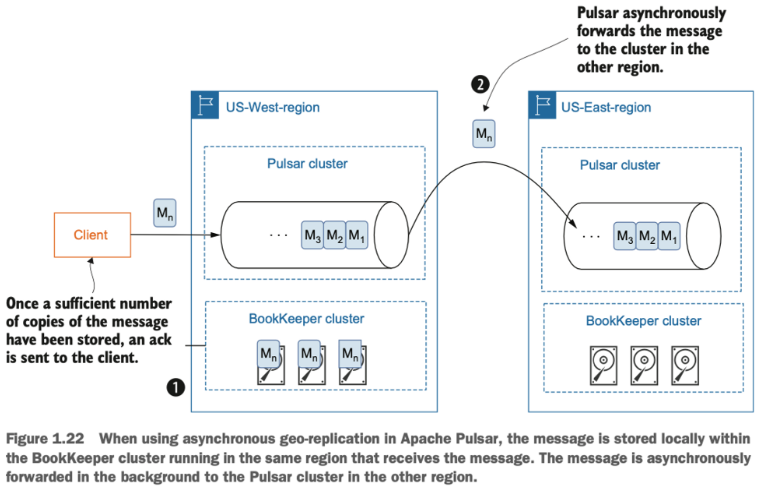
비동기식 지리적 복제를 사용하면, 프로듀서는 다른 데이터 센터들에서 메시지를 받았다는 것에 대한 ack를 기다리지 않습니다. 대신, 프로듀서 메시지가 로컬 BookKeeper 클러스터 내에 성공적으로 영속화(persist)된 즉시 ack를 수신합니다. 그런 다음, 데이터는 Figure 1.22 처럼 근원지(source) 클러스터에서 다른 데이터 센터로 비동기식으로 복제됩니다.
비동기식 지리적 복제는 클라이언트가 다른 데이터 센터로부터의 응답을 기다릴 필요가 없기 때문에 낮은 지연 시간을 제공합니다. 그러나, 비동기식 복제로 인해 결과적으로 더 약한 일관성 보장을 제공합니다. 비동기식 복제에서는 항상 복제에 대한 지연이 있기 때문에, 출발지에서 목적지로 복제되지 않은 어느 정도의 데이터가 항상 존재합니다.
Apache Pulsar에서 동기식 지리적 복제를 설정하는 것은 비동기식보다 약간 더 복잡합니다. 메시지가 과반수 이상의 데이터 센터에서 디스크에 영속화가 되었다는 확인을 받은 이후에만 메시지 acknowledgement 전송되도록 하기 위해서는 일부 수동 설정이 필요하기 때문입니다. Apache Pulsar에서 동기식 지리적 복제를 어떻게 구현할 수 있는지에 대한 자세한 내용은 부록 B에서 다루겠지만, figure 1.23 처럼 Pulsar의 이중 계층(two-tiered) 아키텍처 설계와 Apache BookKeeper 클러스터가 동시에 로컬과 원격 노드, 특히 다른 지리적 지역의 노드로 구성될 수 있는 능력 덕분에 가능하다는 것을 말해드릴 수 있습니다.

동기식 지리적 복제는 모든 물리적으로 사용 가능한 데이터 센터가 데이터 시스템에 대 전역 논리적 인스턴스를 형성하며 가장 높은 수준의 가용성을 제공합니다. 애플리케이션은 어디에 있는 어떤 데이터 센터에서든지 실행될 수 있으며 여전히 데이터에 접근할 수 있습니다. 또한, 다른 데이터 센터 간에 강력한 데이터 일관성을 보장하며, 데이터 센터의 실패가 발생하는 경우에도 수동 작업 없이 애플리케이션에서 쉽게 의존할 수 있습니다.
외부 서비스에 의존하는 다른 메시징 시스템과 달리, Pulsar는 지리적 복제를 내장(built-in) 기능으로 제공합니다. 사용자는 서로 다른 지역의 Pulsar 클러스터 간 데이터의 복제를 쉽게 활성화할 수 있습니다. 복제가 설정되면, 데이터는 프로듀서나 컨슈머의 어떤 상호 작용 없이도 원격지의 클러스터에 지속적으로 복제됩니다. 지리적 복제를 어떻게 설정하는지에 대한 자세한 내용은 부록 B에서 다룹니다.ㅈ