메시징 시스템의 발전 과정 ("Apache Pulsar in Action" 챕터 1.3)
본 포스트는 “Manning Publications”에서 출판하고 현재 StreamNative 에서 무료 배포 중인 책 “Apache Pulsar in Action”의 내용을 정리한 내용입니다. 본 포스트는 비상업적이며 학습 목적으로 작성되었습니다. 전문적인 내용은 반드시 원서를 참조하시기 바랍니다. 모든 저작권은 해당 출판사와 저자에게 있습니다.
링크:
1. 원서(출판사) : https://www.manning.com/books/apache-pulsar-in-action
2. 원서(배포본) : https://streamnative.io/ebooks/get-your-free-copy-of-mannings-apache-pulsar-in-action

1.3 The evolution of messaging systems
지금까지 EMS의 정의와 제공하는 핵심 기능에 대해 자세히 살펴 보았으니, 이제 메시징 시스템의 간략한 역사와 발전 과정에 대해 설명하려고 합니다. 메시징 시스템은 수십 년 동안 존재해 왔으며 많은 조직에서 효과적으로 사용되어 왔습니다. 결국 Apache Pulsar는 새롭게 등장한 신기술이 아니라 메시징 시스템의 진화 과정의 또 다른 단계에 불과합니다. 메시징 시스템의 역사에 대한 컨텍스트을 제공함으로써, Pulsar가 기존의 메시징 시스템과 비교했을 때 어떤 차별점을 가지고 있는지 이해할 수 있기를 바랍니다.
1.3.1 Generic messaging systems
메시징 시스템을 세부적으로 다루기 전에, 메시징 시스템의 단순화된 표현을 제시하여 모든 메시징 시스템이 가지고 있는 기본 구성 요소를 강조하고자 합니다. 이러한 핵심 기능들을 식별하는 것은 시간이 지나면서 메시징 시스템 간의 비교를 위한 기본 지식을 제공할 것입니다.
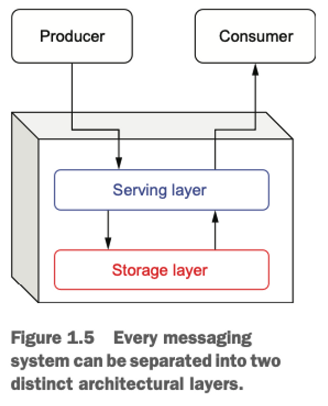
Figure 1.5에서 볼 수 있듯이, 모든 메시징 시스템은 곧 다루게될 각기 고유한 책임을 가진 두 개의 주요 계층으로 구성되어 있습니다. 우리는 각 계층에서의 메시징 시스템의 진화를 살펴보면서 Apache Pulsar를 포함한 다양한 메시징 시스템을 적절하게 분류하고 비교해보겠습니다.
SERVING LAYER
서빙 레이어(serving layer)는 EMS 내에서 메시지 프로듀서와 컨슈머와 직접 상호작용하는 개념적인 계층입니다. 그 주요 목적은 들어오는 메시지를 받아 하나 이상의 목적지로 라우팅하는 것 입니다. DDS, AMQP, MSMQ 등 지원가능한 하나 이상의 메시징 프로토콜을 통해 통신하게되며 결과적으로, 이 계층은 통신을 위한 네트워크 대역폭과 메시지 프로토콜 변환을 위한 CPU에 크게 의존합니다.
STORAGE LAYER
스토리지 레이어(storage layer)는 EMS 내에서 메시지의 영속성(persistence)과 검색(retrieval)을 담당하는 개념적인 계층입니다. 이 계층은 서빙 레이어와 직접 상호작용하여 요청된 메시지를 제공하고, 메시지의 올바른 순서를 유지하는 책임을 가집니다. 따라서, 이 계층은 메시지 저장을 위해 디스크에 크게 의존합니다.
1.3.2 Message-oriented middleware
메시징 시스템의 첫 번째 카테고리는 보통 메시지 지향 미들웨어(Message-Oriented Middleware, MOM)라고 불리며, 서로 다른 네트워크와 운영 체제에서 동작하는 분산 시스템 간의 프로세스 간 통신과 애플리케이션 통합을 제공하기 위해 설계되었습니다. 가장 주목받는 MOM 구현체 중 하나는 1993년에 데뷔한 IBM의 WebSphere MQ입니다.
초기 구현체들은 (보통) 회사의 데이터 센터 내 깊숙한 곳에 위치한 단일 호스트에 배포되도록 설계되었습니다. 이는 단일 실패 지점(Single Point of Failure)이었을 뿐만 아니라, 이 단일 서버가 모든 클라이언트 요청을 처리하고 모든 메시지를 저장하는 책임이 있었기 때문에 시스템의 확장성이 호스트 기계의 물리적 하드웨어 용량에 제한되었다는 것을 의미하며 Figure 1.6에서 보여지고 있습니다. 이러한 단일 서버 MOM 시스템이 서비스할 수 있는 동시 프로듀서와 컨슈머의 수는 네트워크 카드의 대역폭에 의해 제한되었고, 저장 용량은 기계의 물리적 디스크에 의해 제한되었습니다.

사실 이러한 제약 사항들은 IBM 뿐만 아니라, RabbitMQ와 RocketMQ를 포함한 모든 메시징 시스템들이 단일 호스트에서 서비스되도록 설계되었을 때 발생하는 제약 사항입니다. 정확히 말하자면, 이러한 제약 사항은 당시의 메시징 시스템 뿐만 아니라, 하나의 물리적 호스트에서 실행되도록 설계된 모든 종류의 엔터프라이즈 소프트웨어에 적용되는 문제였습니다.
CLUSTERING
결국 이러한 확장성 문제는 이러한 단일 서버 MOM 시스템에 클러스터링 기능을 추가함으로써 해결되었습니다. 이는 여러 단일-서비스 인스턴스가 메시지 처리를 공유하고 어느 정도의 로드 밸런싱을 제공하게 해주었으며, Figure 1.7에서 보여지고 있습니다. MOM이 클러스터링되었음에도 불구하고, 실제로는 각 단일 서비스 인스턴스가 모든 토픽의 하위 집합에 대한 메시지를 서빙하고 저장하는 책임을 가지게 되는 것이었습니다. 이와 유사한 접근법인 샤딩(sharding)이 이 시기에 관계형 데이터베이스에 의해서 채택되어 이 확장성 문제를 해결하였습니다.
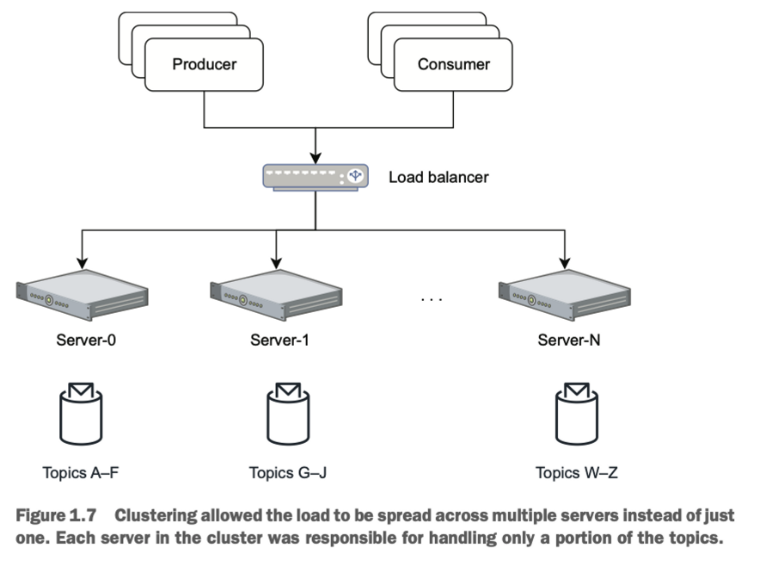
토픽 "핫스팟"이 발생하는 경우, 특정 토픽을 할당받은 불운한 서버는 병목 현상을 일으키거나, 저장 공간을 모두 소진하는 잠재적인 문제가 있습니다. 클러스터 내의 어떤 서버가 실패하면 그 서버가 서비스하고 있던 모든 토픽들도 함께 다운됩니다. 이렇게 클러스터 전체에 대한 실패의 영향을 최소화했지만 (즉, 계속 실행됨), 그 서버가 서비스하고 있던 특정 토픽/큐에 대한 단일 실패 지점이었습니다.
이러한 제약 사항 때문에, 조직들은 메시지 분포를 세밀하게 모니터링하여 토픽 분포가 기본 물리적 하드웨어와 일치하도록 하고, 클러스터 전체에 부하가 고르게 분산되도록 해야 했습니다. 그럼에도 불구하고, 단일 토픽이 문제가 될 가능성이 여전히 남아 있었습니다. 대형 금융 기관에서 일하는 시나리오를 생각해보겠습니다. 당신은 특정 주식에 대한 모든 거래 정보를 단일 토픽에 저장하고, 이 정보를 조직 내의 모든 주식 거래 애플리케이션에 제공하고 싶을 수 있습니다. 이 하나의 토픽에 대한 컨슈머의 수와 데이터의 양은 해당 토픽을 서비스하는 단일 서버를 쉽게 압도할 수 있습니다. 이런 상황에서 필요한 것은 단일 토픽의 부하를 여러 기계에 분산시키는 능력인데, 이것이 바로 분산 메시징 시스템이 수행하는 작업입니다.
1.3.3 Enterprise service bus
엔터프라이즈 서비스 버스(Enterprise Service Bus, ESB)는 XML이 SOAP 기반 웹 서비스를 사용하여 서비스 지향 아키텍처(Service-Oriented Architecture, SOA) 애플리케이션을 구현하는 데 선호되는 메시지 형식이었던, 현재 세기(century) 초반에 등장했습니다. ESB의 핵심 개념은 Figure 1.8에서 보여지는 메시지 버스로, 모든 애플리케이션과 서비스 간의 통신 채널로 작동했습니다. 이 중앙집중식 아키텍처는 이전의 메시지 지향 미들웨어에 의해 사용된 지점-대-지점(point-to-point) 통합과는 대조적입니다.

ESB를 사용하면, 각 애플리케이션 또는 서비스는 단일 통신 채널을 통해 모든 메시지를 주고 받으며, 발행(publish)하고 소비(consume)하려는 특정 토픽 이름을 지정할 필요가 없게됩니다. 각 애플리케이션은 스스로를 ESB에 등록하고 필요로 하는 메시지를 식별하는 데 사용되는 규칙들을 지정하면 ESB는 해당 규칙과 일치하는 메시지들을 동적으로 라우팅하는 데 필요한 모든 로직을 처리합니다. 마찬가지로, 각 서비스는 더 이상 메시지의 목표를 사전에 알 필요가 없고, 단순히 메시지를 버스에 발행하고 메시지가 라우팅되도록 하면 됩니다.
다음 시나리오를 생각해 보겠습니다. 하나의 고객 주문에 대한 수백 개의 개별 항목이 포함된, 거대한 XML 문서가 있습니다. 그리고 당신은 해당 메시지 내의 특정 조건(예: 제품 카테고리 또는 부서별)에 따라 그 해당 항목들의 일부만 서비스로 라우팅하려고 합니다. ESB는 이러한 개별 메시지를 추출(결과에 기반한 XQuery를 통해)하고 메시지의 내용에 따라 다른 컨슈머로 라우팅하는 기능을 제공했습니다
이러한 동적 라우팅 기능 외에도, ESB는 메시지 처리를 컨슈머 애플리케이션에서 수행하는 대신 메시징 시스템 내에서 메시지를 처리함으로써 스트림 프로세싱(stream processing)의 첫 번째 혁신적 단계를 밟았습니다. 대부분의 ESB는 메시지 변환 서비스를 제공했는데, 대부분 XSLT 또는 XQuery를 사용하여 발신 서비스와 수신 서비스 간의 메시지 형식 변환을 처리했습니다. 또한 EBS는 그 전까지 컨슈머 애플리케이션에서 수행하던 메시지 가공 및 처리 기능을 메시지 시스템 자체에서 제공하기 시작했습니다. 이는 이전까지 오직 전송 메커니즘으로 사용되고 있던 메시징 시스템에 대한 새로운 사고 방식이었습니다.
어떻게 보면 ESB이야말로 메시징 시스템의 기본 아키텍처에 세 번째 계층을 도입한 EMS의 첫 번째 세대라고 주장할 수 있습니다. 이는 Figure 1.9에서 보여지고 있습니다. 실제로, 현재 대부분의 현대적인 ESB는 비즈니스 프로세스 흐름 관리를 위한 프로세스 코레오그래피(process choreography), 이벤트 상관 관계 및 패턴 매칭을 위한 복잡한 이벤트 처리, 여러 혁신적인 엔터프라이즈 통합 패턴 구현 등의 고급 컴퓨팅 기능을 지원합니다.

ESB이 메시징 시스템의 진화에 기여한 또 다른 부분은 외부 시스템과의 통합에 초점을 맞춤으로써 메시징 시스템이 처음으로 다양한 비-메시징(non-messaging) 프로토콜을 지원하도록 만든 것입니다. ESB 들은 여전히 AMQP 및 기타 pub-sub 메시징 프로토콜을 완벽하게 지원하지만, ESB의 주요 차별점은 이메일, 데이터베이스, 기타 제3의 시스템과 같은 비-메시지 지향적 시스템(non-message-oriented systems) 간에 데이터를 주고 받을 수 능력이었습니다. 이를 위해 ESB는 개발자가 선택한 시스템과 통합하기 위해 자체 어댑터를 구현할 수 있도록 소프트웨어 개발 키트(SDK)를 제공했습니다.

Figure 1.10에서 볼 수 있듯이, 이는 데이터가 시스템 간에 더욱 쉽게 교환될 수 있게 하여 다양한 시스템의 통합을 단순화했습니다. 이 역할에서 ESB는 메시지 전달 인프라와 프로토콜 변환을 제공하는 시스템 간의 중재자 역할을 병행했습니다.
이처럼 ESB는 혁신과 기능으로 EMS를 확실하게 발전시켰고 오늘날에도 매우 인기가 있음에도 불구하고, ESB는 여전히 단일 호스트에 배포되도록 설계된 중앙집중식 시스템이며 과거 MOM들과 같은 확장성 문제를 겪고 있습니다.
1.3.4 Distributed messaging systems
분산 시스템은 서비스나 기능을 제공하기 위해 함께 작동하는 컴퓨터의 집합으로, 최종 사용자에게는 단일 머신에서 실행되는 것처럼 작동합니다. 분산시스템에는 파일 시스템, 키-값 저장소, 데이터베이스 등이 있습니다. 최종 사용자는 서비스가 여러 대의 머신에 집합이 함께 동작하며 제공되는 사실을 인지하지 못합니다. 분산 시스템은 공유 상태를 가지고, 동시(concurrently)에 작동하며, 하드웨어의 실패가 전체 시스템의 가용성에 영향을 미치지 않도록 할 수 있습니다.
Hadoop 컴퓨팅 프레임워크이 대중화되며 분산 컴퓨팅 패러다임이 널리 채택되기 시작하였고, 단일 호스트의 제약은 해소되었습니다. 이로써 여러 머신에 처리와와 저장을 분산하는 새로운 시스템이 개발되기 시작한 시대가 열렸습니다. 분산 컴퓨팅의 가장 큰 이점 중 하나는 단순히 새로운 하드웨어를 시스템에 추가함으로써 가능한 수평적 확장성(horizontally scalable) 입니다. 성능이 단일 머신의 물리적인 하드웨어에 제한을 받던 이전의 중앙집중식 시스템과 달리, 새롭게 개발되는 시스템들은 이제 수백 대의 머신의 리소스를 쉽고 경제적으로 활용할 수 있게 되었습니다.

Figure 1.11에서 볼 수 있듯이, 메시징 시스템도 데이터베이스, 컴퓨팅 프레임워크와 마찬가지로 분산형 컴퓨팅 패러다임(distributed computing paradigm)으로 전환하였습니다. Apache Kafka를 시작으로 최근에는 Apache Pulsar와 같은 새로운 메시징 시스템들이 분산 컴퓨팅 모델을 채택하여 현대 기업들이 요구하는 확장성과 성능을 제공하고 있습니다.
분산 메시징 시스템에서는 단일 토픽의 내용이 여러 머신에 분산되어 메시지 계층에서 수평적으로 확장 가능한 저장을 제공하는데, 이는 이전의 메시징 시스템에서는 불가능했던 것입니다. 데이터를 클러스터 내의 여러 노드에 분산시키는 것은 데이터의 redundancy와 고가용성(high availability), 메시지 저장 공간의 확장, 메시지 브로커 수 증가에 따른 메시지 처리량의 증가, 시스템 내의 단일 실패 지점(SPOF)의 제거 등 여러 가지 이점을 제공합니다.
분산 메시징 시스템과 클러스터링되는 단일 노드 시스템의 주요 구조적 차이점은 저장 계층이 어떻게 설계되었는지에 있습니다. 이전의 단일 노드 시스템에서는 주어진 토픽에 대한 메시지 데이터가 모두 같은 머신에 저장되어 있어, 로컬 디스크에서 데이터를 빠르게 제공할 수 있었습니다. 그러나 앞서 언급했듯이, 이는 토픽의 크기를 해당 머신의 로컬 디스크 용량에 제한시키는 효과를 낳게됩니다. 분산 메시징 시스템에서는 데이터가 클러스터 내의 여러 머신에 분산되어 있습니다. 이러한 데이터 분산은 단일 머신의 저장 용량을 초과하는 양의 메시지를 하나의 토픽 내에 유지할 수 있게 해주었습니다. 이러한 데이터 분산을 가능케 하는 핵심적 아키텍처 추상은 로그 선행 기록(write-ahead log)으로, 메시지 큐의 내용을 메시지가 저장될 수 있는 쓰기 전용(append-only) 데이터 구조로 다룹니다.
Figure 1.12에서 볼 수 있듯이, 논리적 관점에서 새 메시지가 토픽에 게시되면 해당 메시지는 로그의 끝에 추가됩니다. 그러나 물리적 관점에서는 메시지가 클러스터 내의 어떤 서버에도 작성될 수 있습니다.

분산 메시징 시스템은 이전 세대의 메시징 시스템보다 확장성이 훨씬 뛰어난 저장 계층의 용량을 제공합니다. 분산 메시징 아키텍처의 또 다른 이점은 하나의 토픽에 대한 메시지들을 여러 브로커가 서비스할 수 있는 능력으로, 이는 부하를 여러 머신에 분산시킴으로써 메시지 생산 및 소비 처리량을 증가시킵니다. Figure 1.12을 예로들면, 토픽에 발행된 메시지는 디스크에 각각의 쓰기 경로를 가진 세 개의 별도의 서버에 의해 처리됩니다. 이로써 분산 메시징 시스템은 이전 세대의 메시징 시스템과 달리 부하를 단일 디스크가 아닌 여러 디스크에 분산시키며 더 높은 쓰기 처리량을 제공하게 됩니다. 클러스터 내의 노드에 데이터가 분산되는 방식은 파티션 기반(partition-centric)과 세그먼트 기반(segment-based)의 방식이 있습니다.
PARTITION-CENTRIC STORAGE IN KAFKA
메시징 시스템에서 파티션 기반 전략을 사용할 때, 토픽은 파티션이라는 고정된 수의 그룹으로 나누어집니다. 토픽에 게시된 데이터는 Figure 1.13에서 보여지는 것처럼 파티션에 분산되며, 각 파티션은 토픽에 게시된 메시지의 일부를 수신하게 됩니다. 토픽의 총 저장 용량은 토픽 내의 파티션 수와 각 파티션의 크기를 곱한 것과 같습니다. 이 한계에 도달하면 더 이상 데이터를 토픽에 추가할 수 없습니다. 단순히 클러스터에 브로커를 더 추가하는 것으로는 이 문제를 해결하지 못합니다. 왜냐하면 토픽의 파티션 수를 늘려야 하며 수동으로 진행해야 하기 때문입니다. 추가로, 파티션 수를 늘리면 재분배(rebalance)를 수행해야 하지만 재분배 작업은 비용이 많이 들고 시간이 많이 걸리는 과정입니다 --이 부분은 뒤에서 다시 다루겠습니다.
파티션 중심의 저장 기반 시스템에서는 토픽이 생성될 때 파티션의 수가 지정되며 이는 시스템이 어떤 노드가 어떤 파티션을 저장할 지 등을 결정 할 수 있게 해줍니다. 하지만 파티션 수를 사전에 결정하는 것은 다음의 의도치 않은 몇 가지 부작용을 초래합니다:
- 단일 파티션은 클러스터 내의 단일 노드에만 저장될 수 있으므로, 파티션의 크기는 해당 노드의 사용 가능한 디스크 공간에 제한됩니다.
- 데이터가 모든 파티션에 균등하게 분산되므로, 각 파티션은 토픽 내에서 가장 작은 파티션의 크기로 제한됩니다. 예를 들어, 토픽이 각각 4TB, 2TB, 1TB의 사용 가능한 디스크를 가진 세 노드에 분산되어 있다면, 세 번째 노드의 파티션은 크기가 1TB까지만 커질 수 있으며 이는 토픽 내의 모든 파티션이 1TB까지만 커질 수 있다는 것을 의미합니다.
- 엄격하게 요구되는 것은 아니지만, 각 파티션은 일반적으로 데이터 중복성을 보장하기 위해 여러 노드에 여러 번 복제(replication)됩니다. 따라서, 최대 파티션 크기는 가장 작은 복제본(replica)의 크기로 더더욱 제한됩니다.

용량 제한에 부딪히게 되면, 유일한 해결책은 토픽 파티션 수를 늘리는 것입니다. 하지만 그런 확장은 전체 토픽의 재분배가 요구되며 Figure 1.14에서 보여지는 것과 같습니다. 재분배 과정에서는 기존 노드의 디스크 공간을 확보하기 위해 기존 토픽 데이터가 모든 토픽 파티션에 재분배됩니다. 따라서 기존 토픽에 네 번째 파티션을 추가하면, 재분배 과정 이후 각 파티션에는 총 메시지의 약 25%가 있어야 합니다.
이런 데이터 복사는 비용이 많이 들고 오류가 발생하기 쉽습니다. 왜냐하면 토픽의 크기에 직접 비례하는 만큼의 네트워크 대역폭과 디스크 I/O를 소비하기 때문입니다 (예를 들어, 10TB의 토픽을 재분배하면 10TB의 데이터가 디스크에서 읽히고, 네트워크를 통해 전송되며, 타겟 브로커의 디스크에 쓰여집니다). 재분배 과정이 완료된 후에만 이전에 존재하던 데이터를 삭제하고 토픽이 클라이언트에 서비스를 재개할 수 있습니다. 이처럼 재분배 비용은 무시할 수 없으므로 파티션 크기를 신중하게 선택하는 것이 좋습니다.
데이터에 대한 redundancy 장애 복구(fail-over)를 제공하기 위해, 파티션이 여러 노드에 복제되도록 설정할 수 있습니다. 이는 노드 장애가 발생해도 디스크에 데이터 복사본이 하나 이상 존재하는 것을 보장합니다. 기본 복제 설정은 세 개로, 시스템은 각 메시지의 복사본 3개를 유지하게 됩니다. 이는 redundancy 제공의 여지를 주는 좋은 트레이드 오프이지만, Kafka 클러스터의 크기를 결정할 때 이 추가 저장 요구사항을 고려해야 합니다.

SEGMENT-CENTRIC STORAGE IN PULSAR
Pulsar은 메시지의 영속적 저장소(persistent storage)를 제공하기 위해 Apache BookKeeper 프로젝트에 의존합니다. BookKeeper의 논리적 스토리지 모델은 무한대의 스트림 엔트리를 순차적인 로그(sequentila log)로 저장하는 개념에 기반하고 있습니다. Figure 1.15에서 볼 수 있듯이, BookKeeper 내에서 각 로그는 세그먼트라고 알려진 더 작은 데이터 단위로 나뉘며, 각 세그먼트는 또 다시 여러 로그 엔트리로 구성됩니다. 이 세그먼트들은 이후, redundancy와 확장성을 위해 저장 계층의 —bookies 라 불리는— 여러 노드에 기록됩니다.
Figure 1.15에서 볼 수 있듯이, 세그먼트는 디스크 용량의 여유가 있는 저장 계층 어디든지 배치될 수 있습니다. 새로운 세그먼트를 위한 저장 용량이 부족할 때는, 쉽게 새로운 노드를 추가하고 데이터 저장에 즉시 사용될 수 있습니다. 세그먼트 중심의 저장 아키텍처의 주요 이점 중 하나는 세그먼트가 무한히 생성되고 어디든지 저장될 수 있으므로, 파티션 수에 기반한 수직 및 수평 확장에 인위적 제한을 두는 파티션 중심의 저장과는 달리, 진정한 수평 확장성을 제공한다는 것입니다.
