서버 성능테스트 이야기 2 [ 첫 테스트 ]
Contents
- 지난이야기
- 성능 테스트 목적
- 테스트 제약조건
- 테스트 설정
- 사양 (Specification)
- 테스트 시작
- 서버 지표 분석 : Rate per Second
- 서버 지표 분석 : CPU 사용량
- 서버 지표 분석 : Error Rate & HTTP Duration
- 서버 지표 분석 : Blocked 상태 Thread 수
- 서버 지표분석 : Heap 영역과 JVM 메모리
- 서버 지표 분석 : 결과
지난 이야기
지난 블로그에서는 전체 서비스 구조, 테스트 시나리오, 테스트 툴 K6, 테스트 프로세스 등 테스트 관련 세부사항들을 소개했습니다. 이번 포스트에서는 실제 성능 테스트를 실행하고, 결과를 통해 여러 개선 포인트를 찾아내어 다시 적용해보는 시간을 가지도록 하겠습니다.
성능 테스트 목적
1. 서버의 적정 Throughput을 알아내는 것
"서버가 n-코어 m-기가바이트 메모리, p-Gbps bandwidth 머신에서 초당 몇 개의 요청을 처리한다, 초당 몇 메가바이트의 데이터를 처리한다" 등의 정보를 가지고 있다면 상대적으로 명확한 Scale-Out Operation을 수행할 수 있습니다.
서버의 적정 Throughput이 1000/s 인 것을 확인했다.
다음 주 이벤트에 10,000/s의 트래픽이 예상된다.
로드밸런싱 활용에 따른 비용을 제외하더라도 최소 10대로는 Scale-out 해야 될 것이다.
그러니 사전에 10대로 Scale-out 해서 테스트를 진행해보자.
2. 성능 개선
성능 테스트는 처음이니 1번을 진행하는 과정에서 발견되는 많은 에러 사항이 발견될 것으로 보입니다. 개선이 가능한 부분들은 가능한 개선 해나가며 테스트할 예정입니다.
테스트 제약조건
비즈니스 로직, 애플리케이션 로직은 가급적 건들지 않는다.
- 일반적인 경우 "서버 성능이 떨어지니 로직을 비즈니스 로직을 조금 수정하겠습니다"라는 말이 나올 일이 없기 때문입니다.
- 대신 불필요한 기능, 비효율적인 기능들은 제거 가능합니다.
테스트 대상 서버의 자원은 수정하지 않는다.
- 테스트 목표가 적정 Throughput을 확인하는 것이므로 변수를 만들수록 성능 분석에 어려움이 발생합니다.
- 하지만 인접 서버, 데이터베이스 등 외부에서 병목이 발생할 경우 해당 부분은 빠르게 주저 없이 개선하겠습니다.
테스트 설정
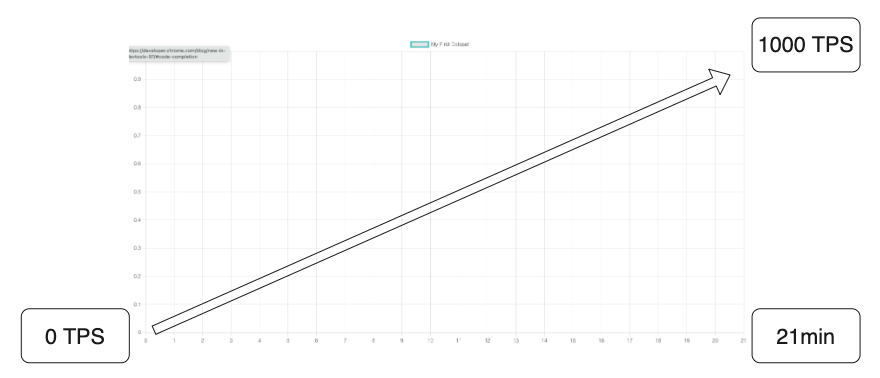
| Category | Value | Comment |
| 진행시간 (Duration) | 21분 | 최소 21분은 진행해야 유의미한 패턴을 관찰할 수 있을것 |
| 동시접속 사용자 (Target User) | 0명부터 1000명까지 21분동안 Linearly Increasing |
|
| Reqeust Frequency | 초당 0회부터 1000회까지 21분동안 Lineary Increasing 사용자가 1초당 1개의 요청을 전송하도록 설정 |
어느시점부터 성능에 이상이 발생하는지 관찰가능 |
사양 (Specification)
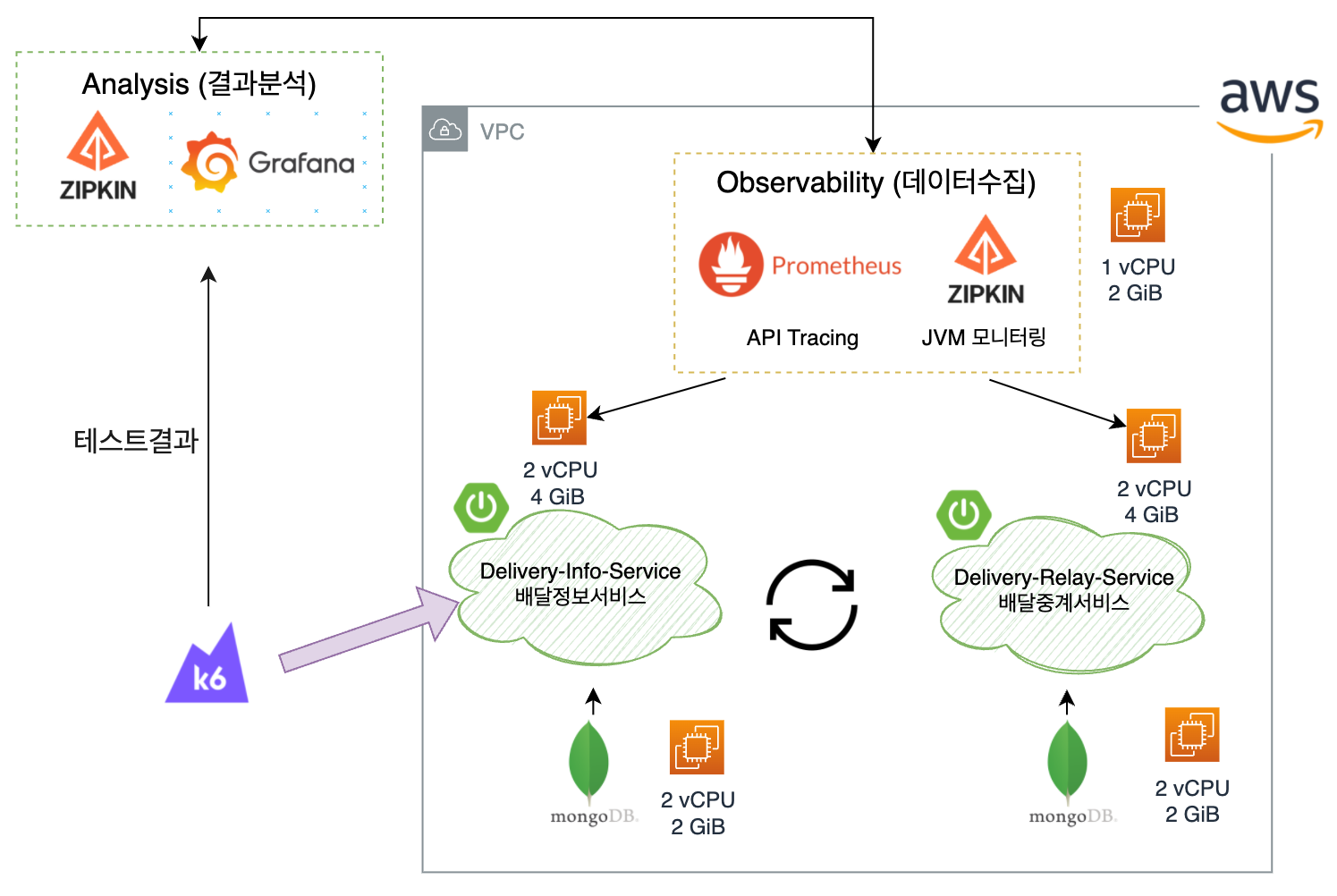
- 테스트 대상인 Delivery-Info-Service(배달정보서비스)는 2 코어, 4 GiB 메모리로 구성했습니다.
- 배달정보서비스와 통신하는 배달중계 서비스도 2 코어, 4 GiB 메모리로 구성했습니다.
- MongoDB도 모두 2코어, 4GiB 메모리로 구성했습니다
- 모니터링 툴인 Prometheus와 Zipkin은 EC2 인스턴스 한 개에서 동작하고 있으며 1 코어, 1 GiB 메모리로 구성했습니다.
- Analaysis(결과 분석) 항목에서 Grafana는 Grafana Cloud를 사용해서 별도 관리가 없습니다. Zipkin 은 Observability 항목과 동일합니다.
- 별도의 언급이 없는 한 다음 포스트에서 위 사양을 가지고 계속 테스트를 진행할 예정입니다.
테스트 시작
끝
서버 지표 분석 : Rate per Second
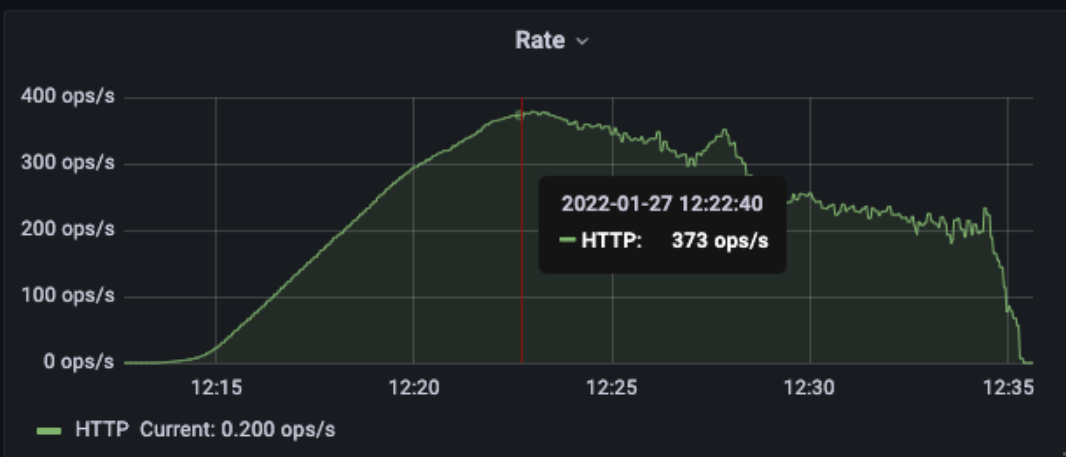
우선 정보서비스와 중계 서비스의 RPS를 살펴보겠습니다. 400/s 근처에서부터 처리량이 반대로 하락하는 것이 보입니다. 저 시점에 서버가 이상 반응을 보였을 것이라 생각이 듭니다.
서버 지표 분석 : CPU 사용량
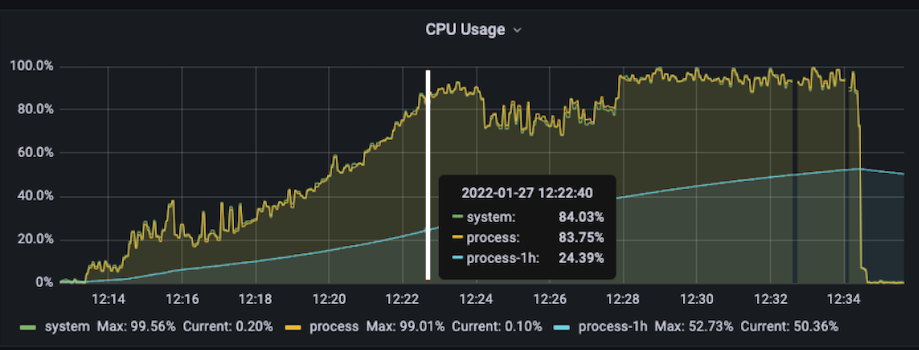
CPU 사용량입니다. 그래프의 최고점은 시스템 CPU 사용량 100%를 나타냅니다. CPU 사용량, 시스템 전체와 Process 사용량이 거의 동일한 것을 보아하니 서버 JVM 프로세스 외에 CPU에 영향을 끼치는 프로세스는 없는 것을 확인할 수 있습니다.
위 그래프에 표시된 흰색 수직선은 동시접속자 수가 400명 구간을 찍은 시점입니다. 그 시점에 이미 CPU 사용량 90%에 도달했으며, 이후 잠시 cool down period를 거쳐 CPU에 제대로 과부하가 발생하는 것을 확인할 수 있습니다.
CPU를 최대한으로 유지하는 것이 효과적인 운용방법이 아닌가?라고 생각했었지만, 멘토님에게 여쭤보니 safety와 stability를 전부 고려해서 평균 CPU 사용량을 30~70%로 유지한다고 합니다. 전설에 의하면 StackOverflow는 10% CPU Usage를 유지한다고도 하더군요. 저도 테스트를 거치면서 최적의 CPU 사용량을 설정하는 것이 운용하는 측면에서 유리할 것으로 보입니다.
서버 지표 분석 : Error Rate & HTTP Duration
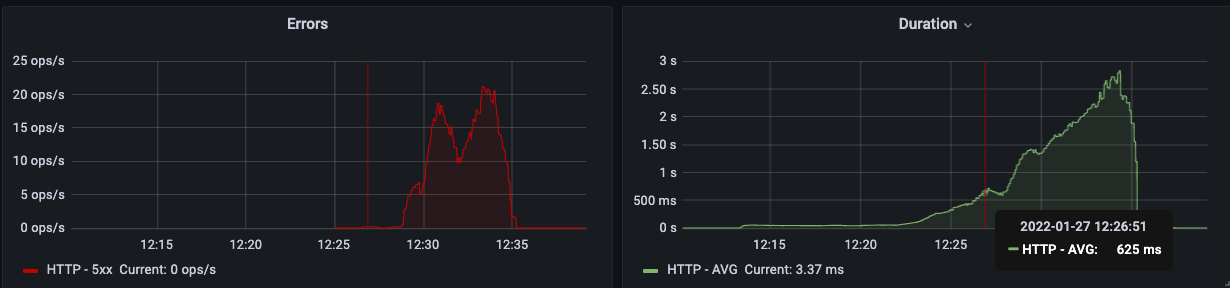
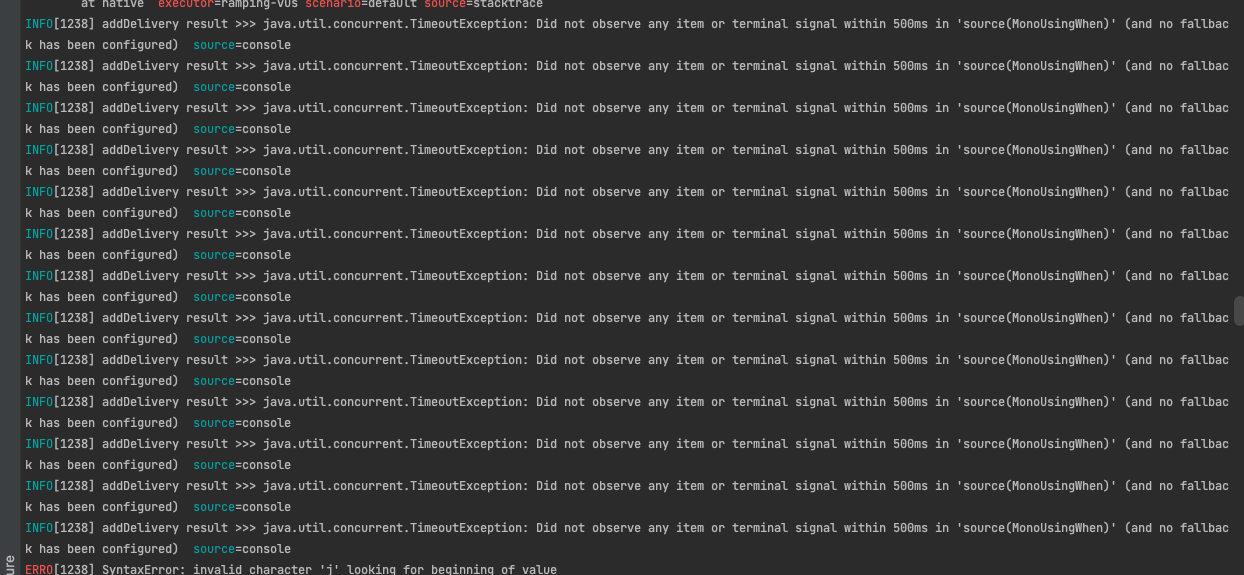
위 그래프는 에러 발생비율(좌)과 HTTP Request 평균 소요시간(우)을 나타냅니다. HTTPRequest 평균 요청 시간이 500ms을 넘어가면서 (없던) 에러 발생 빈도가 빠르게 증가했습니다. 여기서 500ms라는 시간을 명시적으로 표현하는 이유는 발생한 Error들이 모두 제가 repository.save() 메서드에 걸어놓은 프로젝트 리액터의 timeout()과 retryBackOffSpec()가 발동되며 발생한 에러이기 때문입니다.
아래는 제가 캡처한 테스트 로그입니다.

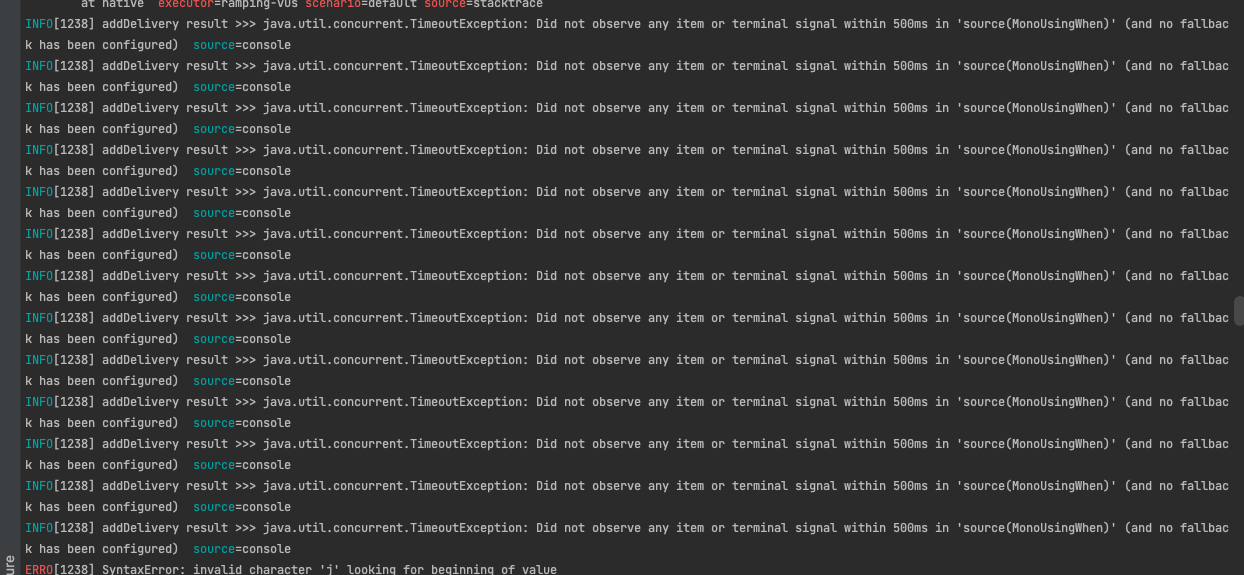
위 에러 그래프를 보면 아시겠지만 서버에서 정말 많은 StackTrace가 발생하고 있었습니다. StackTrace는 JVM 성능에 큰 부담이 되는데요, 이 부분에 대해서는 Exception의 StackTrace를 벤치마킹한 블로그 포스트 , 또는 Java StrackTrace 동작원리 관련 글 확인을 추천드립니다. 간략하게 이야기하자면 에러 발생 시 스레드는 Stack Frame 을 하나하나 pop() 해가면서 에러 발생 지점을 확인해나가기 때문입니다. Thread-per-Request 모델에서도 이미 성능저하의 원인이지만 EventLoop 쓰레드 모델처럼 소수의 스레드를 유지하는 Netty에서는 더욱 치명적일 수도 있을 것이라는 생각이 듭니다.
그렇다면 과연 StackTrace 생성 작업을 최소화함으로써 CPU 성능 향상에 얼마나 더 많은 도움이 될지, 그리고 그에 따라 요청 처리량(RPS)에 유의미한 상승을 발생시킬 수 있을지 한번 확인해보겠습니다.
이번 분석의 Error Rate, HTTP Duration 그리고 RetryTimeout을 통해 도출해낼 수 있는 개선 포인트는 Retry 사용을 제거해서 StackTrace를 최소화입니다. 이 부분 기록해두겠습니다.
서버 지표 분석 : Blocked 상태 Thread 수
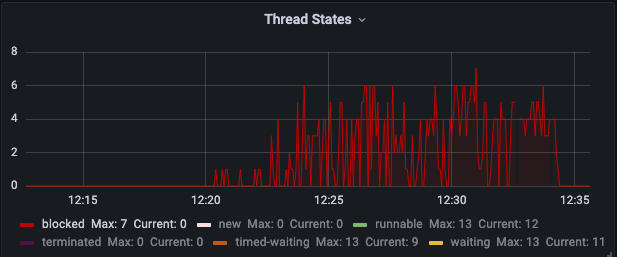
위 그래프는 blocked 상태인 스레드 갯수를 나타내는 그래프입니다. 좌측 배달정보서비스의 그래프를 보면 동시접속 400명을 넘어가는 순간부터 blocked 상태의 쓰레드의 갯수가 증가하는 것이 보입니다. 무엇인가 문제가 있는것 같습니다.
현재 프로젝트는 Webflux에 내장되어있는 Netty를 사용하고 있습니다. 비동기 네트워크 프레임워크 Netty는 쓰레드 수를 한정해서 콘텍스트 스위칭을 최소화함으로써 자원의 자원 가용성을 높이고 성능 향상이라는 결과를 만들어냅니다.
보면 BLOCKED 상태의 스레드가 발생한 시점이 동시접속 사용자 400 부분입니다. 과부하에 의해 JVM 어디선가 스레드를 블로킹하는 상황을 짐작해봅니다. 단순하게 생각하면 블로킹되는 원인을 찾고 블로킹이 안되게 변경해줌으로써 Throughput을 증가시킬 수 있을 것입니다. 이 이 부분도 체크해두고 성능개선에 참고하도록 하겠습니다.
서버 지표분석 : Heap 영역과 JVM 메모리
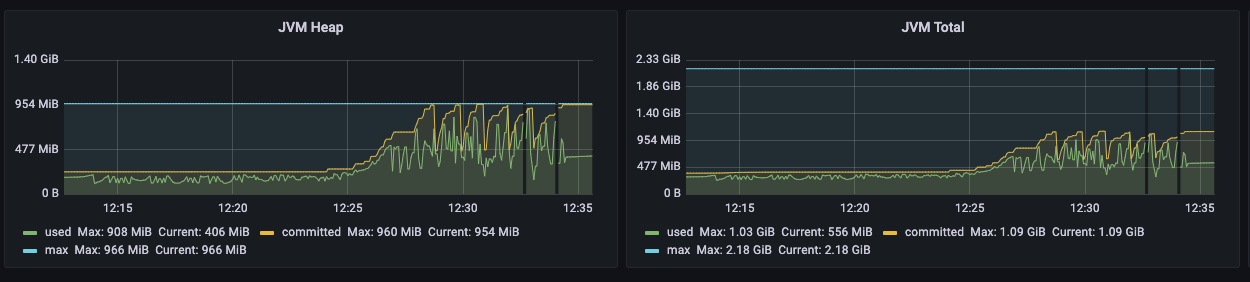
분석 가능한 포인트가 정말 많지만 시간 관계상 마지막으로 Heap 영역(좌)과 JVM 전체 메모리(우)를 살펴보겠습니다. 두 그래프 모두 최대 크기를 나타내는 파란색 수평선이 있습니다.
우측의 JVM 전체 메모리를 보면 공간이 여유롭지만 좌측의 Heap영역의 메모리는 최대치까지 올라갑니다.
좌측 그래프를 보면 일정한 주기로 GC가 발생하며 메모리를 유지하는 것을 확인할 수 있습니다.
잦은 GC 실행으로 인해 CPU에 부담이 갔다는 추론을 해보겠습니다.
Minor GC 도 stop-the-world 이벤트이기 때문에 위 "Block 상태 Thread 수" 부분에서 언급한 스레드 블로킹 현상이 발생할 가능성이 충분히 있습니다.
그렇다면 JVM 메모리를 증가시킴으로써 성능 개선 효과를 볼 수 있을 것으로 보입니다. 이 부분도 체크해두겠습니다.
서버 지표 분석 : 결과
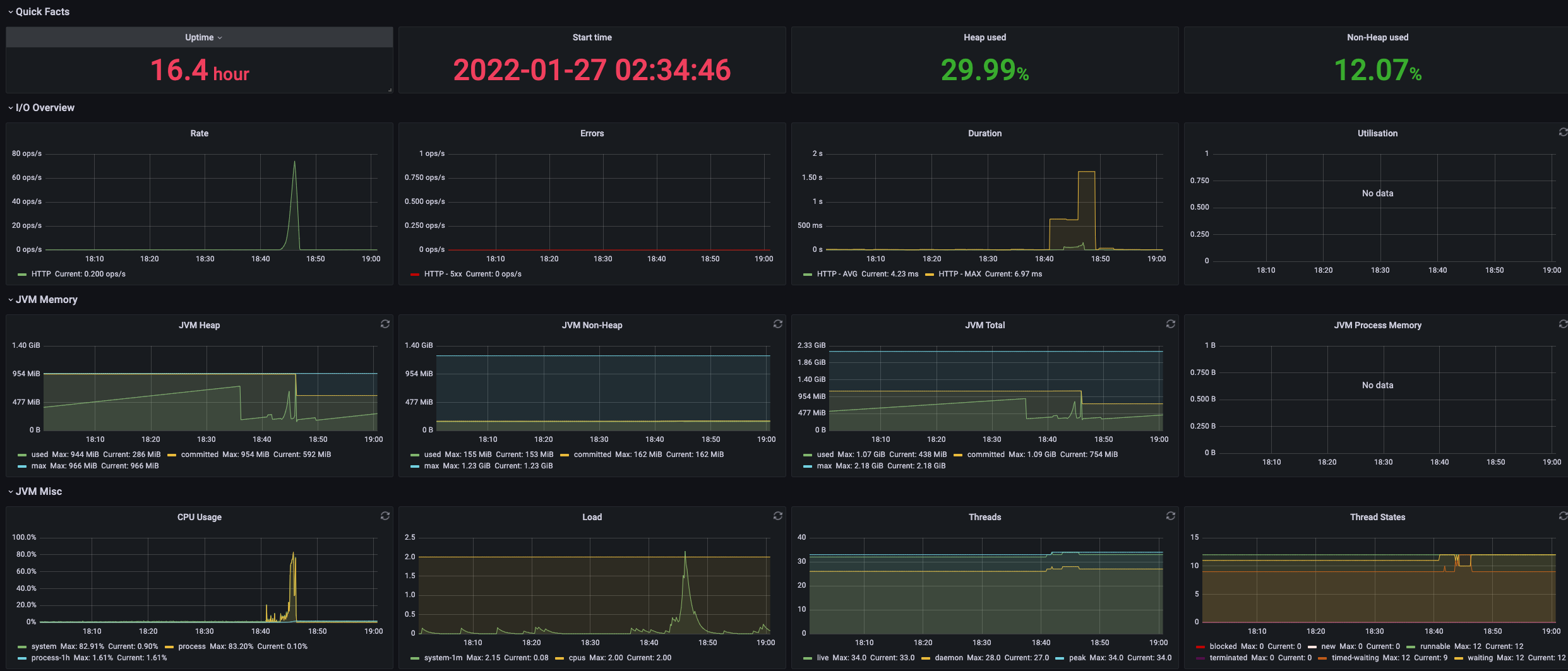
지금까지 서버 성능지표 분석을 통해 서버 분석 시간을 가졌고 다음과 같은, 몇 가지 개선 포인트들을 도출해냈습니다.
모든 모니터링 지표를 커버하는 것은 사실 overfit의 여지도 있거니와 풀타임으로 공부 중인 저에게 시간적으로 부담스러운 일이니 위 세 가지를 가지고 하나씩 적용해가며 성능 개선을 진행해보겠습니다.
- JVM 메모리 영역 확장 (from 서버 분석 : Heap 영역과 JVM 메모리)
- 스택트 레이스 최소화 (from Error Rate + HTTP Duration = StackTrace)
- 블로킹 최소화 (from Block 상태 Thread 수)
오버핏의 좋은 Example Graph

이제 성능개선 적용 테스트를 시작해보겠습니다.
